为什么使用多智能体?
智能体是一个使用 LLM 来决定应用程序控制流的系统。随着你开发这些系统,它们可能会随着时间的推移变得越来越复杂,使得管理和扩展变得更加困难。例如,你可能会遇到以下问题:
- 智能体有太多工具可供使用,导致在决定下一步调用哪个工具时做出糟糕的决策
- 上下文变得过于复杂,单个智能体难以跟踪
- 系统中需要多个专业领域(例如,规划器、研究员、数学专家等)
在多智能体系统中,智能体之间需要相互通信。它们通过交接(handoffs)来实现这一点——这是一种描述将控制权交给哪个智能体以及向该智能体发送什么负载的原始操作。
两种最流行的多智能体架构:
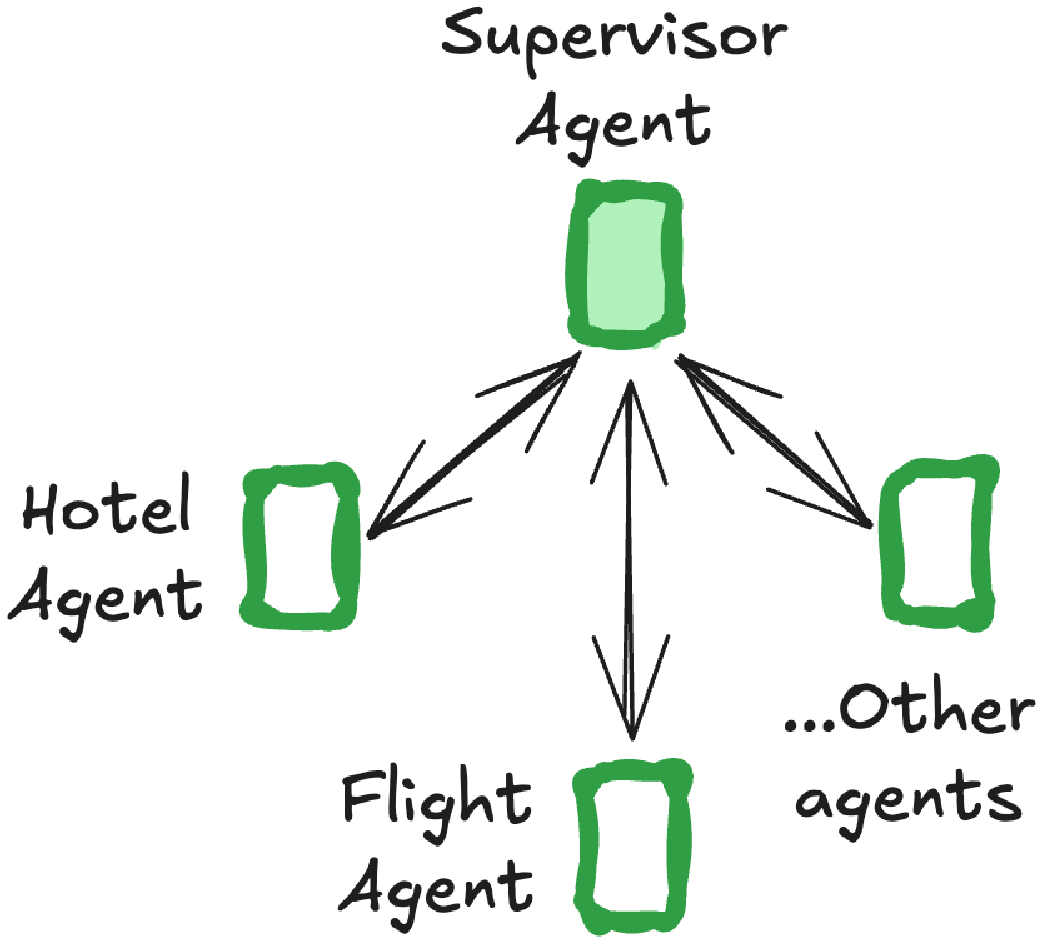
- 主管(supervisor)—— 各个智能体由一个中央主管智能体协调。主管控制所有的通信流和任务委派,根据当前上下文和任务需求决定调用哪个智能体。
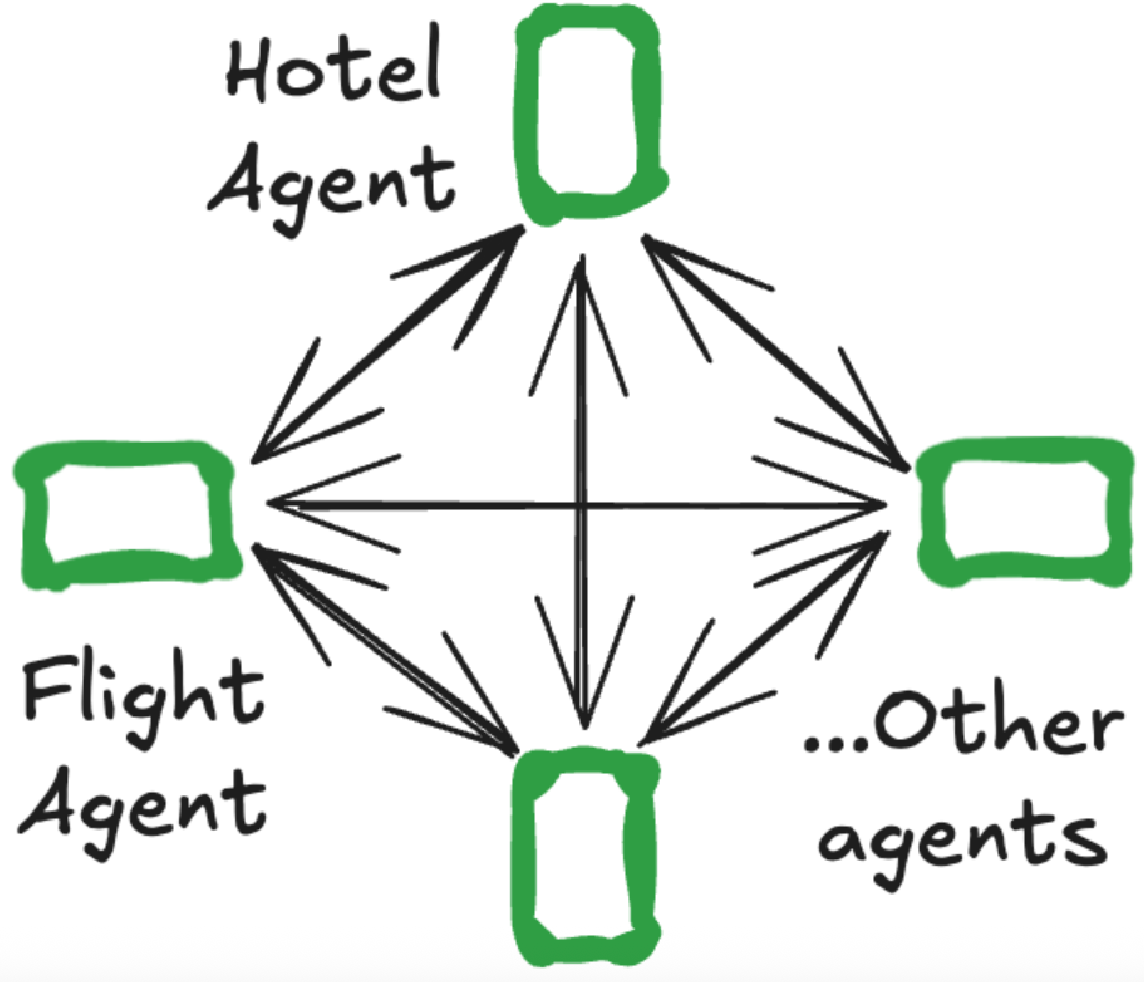
- 群组(swarm)—— 智能体根据各自的专长动态地将控制权移交给彼此。系统会记住最后一个活跃的智能体,以确保在后续交互中,对话能从该智能体恢复。
主管型多智能体(Supervisor)
- 一个中央智能体协调所有子智能体
- 所有控制流决策集中在主管节点
安装依赖
1 | pip install langgraph-supervisor |
示例代码
1 | from langgraph_supervisor import create_supervisor |
群组型多智能体(Swarm)
- 无主管,智能体根据专长动态交接
- 系统会记录“最后活跃的智能体”,对话自动恢复
安装依赖
1 | pip install langgraph-swarm |
示例代码
1 | from langgraph_swarm import create_swarm |
案例
先创建两个智能体
data_search_agent.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112# @Time:2025/10/10 11:11
# @Author:jinglv
from langchain_core.tools import tool
from langgraph.config import get_stream_writer
from langgraph.prebuilt import create_react_agent
from app.agent.model.llms import qv_llm
def database_search(sql: str) -> str:
"""
使用数据库进行搜索
:param sql: sql语句
:return:
"""
writer = get_stream_writer()
writer(f"开始执行【数据库查询工具】,执行的sql为:{sql}")
if "查询数据" in sql:
return "用户注册注册功能"
else:
return "无匹配内容"
def web_search(query: str) -> str:
"""
使用网页进行搜索
"""
writer = get_stream_writer()
writer(f"开始执行【网络搜索】工具,搜索的内容为:{query}")
if "用户登录" in query:
return "用户注册注册功能"
else:
return "无匹配内容"
# 向量数据库语义查询
def vector_database_search(query: str) -> str:
"""
向量数据库查询
:param query: 查询内容
:return:
"""
writer = get_stream_writer()
writer(f"开始执行【向量数据库查询】,查询的问题为:{query}")
result = """
功能说明文档:
#### 📌 F1.1 用户注册
##### 🧩 功能背景
新用户通过注册方式创建账户,支持邮箱/用户名+密码的注册方式。
##### 🚶 主流程
1. 用户打开注册页,填写注册信息
2. 系统校验格式与唯一性(用户名、邮箱)
3. 提交注册,后台创建账户,初始状态为“正常”
4. 注册成功后自动登录并跳转首页
##### ⚠️ 异常流程
- 邮箱/用户名已被注册:提示“已存在”
- 两次密码不一致:提示用户重新输入
##### 📌 状态规则
- 新用户状态为 “正常”
- 注册时间记录为创建时间,头像为默认图
##### 📌 业务规则
- 用户名唯一,支持 4~20 位字母数字组合
- 密码长度不少于 6 位
- 邮箱必须符合格式 `xxx@xxx.xx`
"""
if "用户注册" in query:
return result
else:
return "无匹配内容"
# 创建一个用于数据搜索的智能体
data_search_agent = create_react_agent(
# 设置agent的名字
name="data_search_agent",
# 配置模型
model=qv_llm,
# 绑定工具
tools=[database_search, web_search, vector_database_search],
prompt="""
你是一位数据检索专家,擅长从多种数据源中查找信息,包括结构化数据库、网页和向量数据库。
你拥有以下三种工具,每种工具适用于不同的场景:
1. `database_search(sql)`
- 检索结构化信息,如:接口文档、需求文档、测试用例。
- 适合精确字段查询。
2. `web_search(query)`
- 检索互联网公开网页,适合实时性或广泛性问题。
3. `vector_database_search(query)`
- 检索语义相关文档,如模糊表达、知识库、上下文相关资料。
行为准则:
- 优先根据语义理解选择合适工具。
- 如果一个工具未检索成功,请尝试更换表达方式或使用其他工具。
- 最多连续尝试不超过10次。超过10次,请停止任务并输出:“未找到相关内容,请补充更详细的功能描述或需求信息。”
注意点:
如果是调用数据库查找数据,则需要你先查询数据库中的表结构,然后根据表结构和用户的需求,编写对应的sql语句,调用该数据库操作的工具,执行sql语句,并返回执行的结果,
每一步执行完都需要去分析当前的执行进度,以及规划下一步的任务执行
输出要求:
- 展示最终有用的信息,展示任何工具调用过程。
"""
)
case_genarator_agent.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61# @Time:2025/10/10 11:15
# @Author:jinglv
from langchain_core.tools import tool
from langgraph.config import get_stream_writer
from langgraph.prebuilt import create_react_agent
from app.agent.model.llms import qv_llm
def generate_test_case(requirement: str) -> str:
"""
根据需求生成测试用例
:param requirement: 需求文档
:return:
"""
writer = get_stream_writer()
writer(f"开始执行【需求生成测试用例】工具,需求文档的内容为:{requirement}")
return "1、正常登录,2、密码为空"
# 覆盖率校验的工具
def coverage_check(test_case: str) -> str:
"""
检查测试用例的覆盖率
:param test_case: 测试用例
:return:
"""
writer = get_stream_writer()
writer(f"开始执行【检查测试用例的覆盖率】工具,测试用例的内容为:{test_case}")
return "覆盖率100%"
# 创建一个用于测试用例生成的智能体
test_case_agent = create_react_agent(
model=qv_llm,
tools=[generate_test_case, coverage_check],
name="test_case_agent",
prompt="""
你是一位资深测试专家,擅长根据需求文档自动生成高质量的测试用例,并进行用例覆盖率校验。
你拥有以下两个工具:
1. `generate_test_case(requirement)`
- 输入需求 → 输出测试用例
2. `coverage_check(test_case)`
- 输入测试用例 → 检查覆盖率
任务流程:
1. 根据输入的“需求描述”调用 `generate_test_case`
2. 生成测试用例后立即调用 `coverage_check` 验证覆盖率
3. 如果存在遗漏,返回诊断信息并补充用例
4. 直到覆盖率达到 100%,才输出最终结果
❗特别注意:
- 如果输入的需求信息过于模糊或不完整,无法生成有意义的测试用例:
→ 请直接返回:“无法生成测试用例,请补充更完整的需求说明或接口文档。”
- 请勿暴露工具调用过程,仅返回结构化、清晰的测试用例列表
"""
)
主管型智能体(Supervisor)
1 | # @Time:2025/10/10 13:53 |
群组型多智能体(Swarm)
1 | # @Time:2025/10/10 14:25 |
架构对比总结
| 架构类型 | 控制流设计 | 调度角色 | 灵活性 | 适用场景 |
|---|---|---|---|---|
| Supervisor | 中央调度 | 统一主管 | 中等 | 中小型、结构化任务 |
| Swarm | 分布协商 | 去中心化 | 高 | 动态协作、多专业系统 |
| 自定义图(StateGraph) | 明确控制流 | 无/可选 | 高 | 高度可控流程需求 |