1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
|
"""
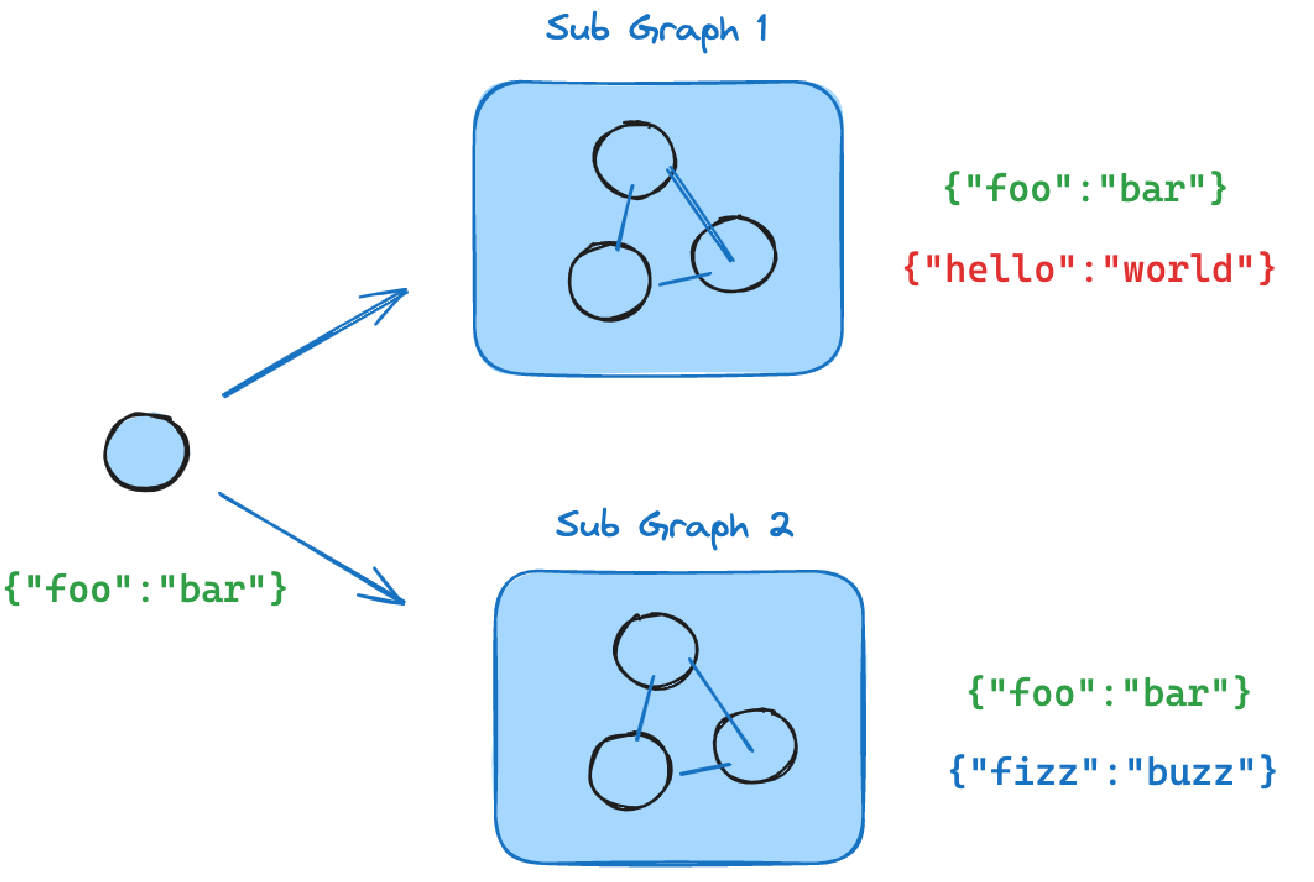
父子工作流(状态共享)
主工作流:
1. 用户输入需求文档
2. 分析出所有的测试点的子工作流:基于需求整理测试点 ---> 验证测试点覆盖率 --->对于覆盖率的测试点补全 --->输出所有的测试点
3. 基于上一个节点生成的测试点生成指定格式的测试用例
父子图(工作流)需要共享的数据(父子状态中的数据一致)
1. 需求文档
2. 生成的测试点
"""
from typing import TypedDict, List
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.config import get_stream_writer
from langgraph.graph import StateGraph, START, END
from langgraph.types import Command
from pydantic import BaseModel
from app.agent.model.llms import qv_llm
class State(TypedDict):
"""主工作流的状态"""
input_requirement: str
test_point: str
test_cases: str
test_case_coverage_report: str
class StateSub(TypedDict):
"""子工作流的状态"""
input_requirement: str
test_point: str
coverage_report: str
def generate_test_points(state: StateSub):
"""基于需求文档生成测试点"""
writer = get_stream_writer()
writer("【开始执行节点】:基于需求文档生成测试点")
input_requirement = state.get("input_requirement")
prompt = PromptTemplate(
input_variables=["document"],
template="""
- Role: 资深测试工程师
- Background: 用户需要根据需求文档生成测试用例,要求以“功能正常+边界+异常”为主线思维指导生成测试点,以确保软件功能的完整性和稳定性。
- Profile: 你是一位经验丰富的资深测试工程师,精通软件测试理论与实践,擅长从需求文档中挖掘测试点,能够全面覆盖功能正常、边界条件和异常情况。
- Skills: 你具备需求分析能力、测试用例设计能力、边界值分析能力、异常处理能力以及对软件质量的敏锐洞察力。
- Goals: 根据用户提供的需求文档,生成全面且详细的测试点,确保测试用例能够覆盖功能正常、边界条件和异常情况。
- Constrains: 生成的测试点需遵循“功能正常+边界+异常”的主线思维指导,格式需清晰、规范,便于理解和执行。
- OutputFormat: 按照示例格式输出测试点,分为“正向验证”“边界测试”“异常处理”三个部分。
- Workflow:
1. 仔细阅读需求文档,理解功能描述和业务逻辑。
2. 根据功能描述,列出功能正常情况下的测试点。
3. 分析功能的边界条件,设计边界测试点。
4. 考虑可能出现的异常情况,设计异常处理测试点。
- Examples:
- 示例1:需求文档描述了一个登录功能,包括用户名和密码验证。
└─ 正向验证
├─ 输入正确的用户名和密码,成功登录
├─ 登录后跳转到正确的页面
└─ 多次登录后仍能正常跳转
└─ 边界测试
├─ 用户名长度为最小值时登录
├─ 密码长度为最大值时登录
└─ 用户名或密码为空时登录
└─ 异常处理
├─ 输入错误的用户名,提示“用户名不存在”
├─ 输入错误的密码,提示“密码错误”
└─ 网络异常时登录,提示“网络连接失败,请重试”
- 示例2:需求文档描述了一个文件上传功能,包括文件大小和格式限制。
└─ 正向验证
├─ 上传符合大小和格式要求的文件,成功上传
├─ 上传后文件在服务器正确存储
└─ 上传多个文件后仍能正常操作
└─ 边界测试
├─ 上传文件大小为最小值时的情况
├─ 上传文件大小为最大值时的情况
└─ 上传文件格式为支持的边缘格式时的情况
└─ 异常处理
├─ 上传超过大小限制的文件,提示“文件过大”
├─ 上传不支持格式的文件,提示“不支持的文件格式”
└─ 网络异常时上传,提示“上传失败,请检查网络连接”
input:{document}
""")
chain = prompt | qv_llm
response = chain.invoke({"document": input_requirement})
test_point = response.content
return {"test_point": test_point}
def verify_test_points_coverage(state: StateSub):
"""验证测试点的覆盖率"""
writer = get_stream_writer()
writer("【开始执行节点】:验证测试点的覆盖率")
prompt = PromptTemplate(
input_variables=["test_point", "document"],
template="""
你是一位资深的软件测试工程师,请根据提供原始的需求文档和测试点,去分析
原始功能文档:
{document}
测试点:
{test_point}
如果测试点覆盖了需求中所有的功能,则直接回复:测试点已经全部覆盖
如果没有全部覆盖,请给出覆盖率分析报告
""")
chain = prompt | qv_llm
response = chain.invoke({
"test_point": state.get("test_point"),
"document": state.get("input_requirement")
})
coverage_report = response.content
return {"coverage_report": coverage_report}
def complete_test_points(state: StateSub):
"""补全生成测试点"""
writer = get_stream_writer()
writer("【开始执行节点】:补全生成测试点")
prompt = PromptTemplate(
input_variables=["test_point", "document", "coverage_report"],
template="""
你是一位资深的软件测试工程师,请根据原始的需求文档和测试点和覆盖分析报告,去补充未覆盖的测试点,添加在输入的测试点后面
原始功能文档:
{document}
输入的测试点:
{test_point}
覆盖分析报告:
{coverage_report}
""")
chain = prompt | qv_llm
response = chain.invoke({
"test_point": state.get("test_point"),
"document": state.get("input_requirement"),
"coverage_report": state.get("coverage_report")
})
test_point = response.content
return {"test_point": test_point}
def output_all_test_points(state: StateSub):
"""输出所有的测试点"""
writer = get_stream_writer()
writer("【开始执行节点】:输出所有的测试点")
return {"test_point": state.get("test_point")}
def route_dispatch(state: StateSub):
"""路由分派"""
writer = get_stream_writer()
writer("【开始执行节点】:根据测试点的覆盖情况进行路由分发")
if "测试点已经全部覆盖" in state["coverage_report"]:
return "输出所有测试点"
else:
return "补全生成测试点"
workflow = StateGraph(StateSub)
workflow.add_node("生成测试点", generate_test_points)
workflow.add_node("验证测试点覆盖率", verify_test_points_coverage)
workflow.add_node("路由分派", route_dispatch)
workflow.add_node("补全生成测试点", complete_test_points)
workflow.add_node("输出所有测试点", output_all_test_points)
workflow.add_edge(START, "生成测试点")
workflow.add_edge("生成测试点", "验证测试点覆盖率")
workflow.add_conditional_edges("验证测试点覆盖率", route_dispatch, ["补全生成测试点", "输出所有测试点"])
workflow.add_edge("补全生成测试点", "验证测试点覆盖率")
workflow.add_edge("输出所有测试点", END)
graph_sub = workflow.compile(checkpointer=True)
class TestCaseModel(BaseModel):
"""测试用例数据模型"""
case_id: str
case_name: str
priority: str
preconditions: str
test_steps: str
test_data: str
expected_result: str
actual_result: str | None
def generate_test_case(state: State):
"""基于测试点生成特定格式的测试用例"""
writer = get_stream_writer()
writer("【开始执行节点】:基于测试点生成特定格式的测试用例")
prompt = PromptTemplate(
input_variables=["test_point", "test_cases", "test_case_coverage_report"],
template="""
你是一位资深测试工程师,请基于下面功能整理的出来的测试点,生成标准的测试用例,
输入测试点:
{test_point}
如果提供已经编写的测试用例和覆盖率分析报告,则在提供的测试用例基础和覆盖率分析报告的基础上补充生成未覆盖测试点的用例
已经生成的用例:
{test_cases}
覆盖率分析报告:
{test_case_coverage_report}
如果没有提供已经编写的测试用例则根据测试点直接生成:
输出的用例,包含测试用例的八要素,:
用例编号(case_id)
用例名称(case_name)
优先级(priority)
前置步骤(preconditions)
测试步骤(test_steps)
输入数据(test_data)
预期结果(expected_result)
实际结果(actual_result)
要以json格式输出,输出格式要求为:
[
{{
"case_id": "用例编号",
"case_name": "用例名称",
"priority": "优先级",
"preconditions": "前置步骤",
"test_steps": "测试步骤",
"test_data": "输入数据",
"expected_result": "预期结果",
"actual_result": "实际结果"
}},
...
]
"""
)
parser = JsonOutputParser(pydantic_schema=List[TestCaseModel])
chain = prompt | qv_llm | parser
response = chain.invoke({
"test_point": state.get("test_point"),
"test_cases": state.get("test_cases"),
"test_case_coverage_report": state.get("test_case_coverage_report")
})
return {"test_cases": response}
def verify_testcase_coverage(state: State):
"""验证测试用例的覆盖率"""
writer = get_stream_writer()
writer("【开始执行节点】:开始验证用例覆盖率")
prompt = PromptTemplate(
input_variables=["test_cases", "test_point"],
template="""
你是一位资深测试工程师,请根据用户下面提供的测试点和测试用例,去分析测试用例是否覆盖了所有的测试点
已经生成的测试用例:
{test_cases}
需要测试的测试点:
{test_point}
输入要求:
如果全部覆盖则直接返回:已覆盖全部测试点
如果没有全部覆盖则返回测试点覆盖分析报告
"""
)
chian = prompt | qv_llm
response = chian.invoke({
"test_cases": state.get("test_cases"),
"test_point": state.get("test_point")
})
result = response.content
if "已覆盖全部测试点" in result:
return Command(goto="保存测试用例")
else:
return Command(goto="生成测试用例", update={"test_case_coverage_report": result})
def save_test_cases(state: State):
"""保存测试用例"""
writer = get_stream_writer()
writer("【开始执行节点】:保存测试用例")
writer(state.get("test_cases"))
main_workflow = StateGraph(State)
main_workflow.add_node("生成测试点", graph_sub)
main_workflow.add_node("生成测试用例", generate_test_case)
main_workflow.add_node("验证测试用例覆盖率", verify_testcase_coverage)
main_workflow.add_node("保存测试用例", save_test_cases)
main_workflow.add_edge(START, "生成测试点")
main_workflow.add_edge("生成测试点", "生成测试用例")
main_workflow.add_edge("生成测试用例", "验证测试用例覆盖率")
main_workflow.add_edge("保存测试用例", END)
graph = main_workflow.compile(checkpointer=InMemorySaver())
if __name__ == '__main__':
response = graph.stream({"input_requriment": """
功能说明文档:
#### 📌 F1.1 用户注册
##### 🧩 功能背景
新用户通过注册方式创建账户,支持邮箱/用户名+密码的注册方式。
##### 🚶 主流程
1. 用户打开注册页,填写注册信息
2. 系统校验格式与唯一性(用户名、邮箱)
3. 提交注册,后台创建账户,初始状态为“正常”
4. 注册成功后自动登录并跳转首页
##### ⚠️ 异常流程
- 邮箱/用户名已被注册:提示“已存在”
- 两次密码不一致:提示用户重新输入
##### 📌 状态规则
- 新用户状态为 “正常”
- 注册时间记录为创建时间,头像为默认图
##### 📌 业务规则
- 用户名唯一,支持 4~20 位字母数字组合
- 密码长度不少于 6 位
- 邮箱必须符合格式 `xxx@xxx.xx`
"""},
subgraphs=True,
stream_mode=["messages", "custom"],
config={"configurable": {"thread_id": "thread_001"}})
for chunk in response:
if chunk[1] == "custom":
print()
print(chunk[2])
elif chunk[1] == "messages":
print(chunk[2][0].content, end="", flush=True)
|