上一讲介绍了Vibe Coding的基本概念、Enterprise SDLC(企业级软件开发生命周期)的标准流程,以及多款优秀的AI编程工具。本章将正式基于这一流程,开启产品的实战开发。
我是一名拥有十多年经验的测试工程师,对测试工作中的效率提升有自己的一套思路和设计方案。因此,本次实战项目定位于构建一个企业级AI驱动的测试平台,并选用Claude Code作为核心AI编程工具。整个开发遵循以下流程:
项目立项
明确项目定位。业务价值与核心边界,通俗的说把“要做什么解决什么问题,达成什么效果”梳理清楚。
本项目的明确目标:建设一套AI驱动的测试工作流程,全面提升测试效率。平台以自然语言交互为入口,用户无需手动编写复杂的测试资产(如测试脚本、数据配置等),只需上传或解析文档、Web站点、源代码等信息,并输入测试目标、业务问题或分析需求,系统即可自动完成测试需求分析、各阶段高质量用例生成、数据统计分析等核心任务,最终输出专业、直观的测试数据看板,实现 “自然语言提问 → 自然语言信息分析 → 智能可视化展示” 的一站式体验。
需求分析
明确项目整体技术方案,完成核心技术栈选型,为后续研发落地提供可靠依据。
做法:使用主流大模型,将项目需求与业务场景输入模型,利用其深度检索(Deep Search)能力,自动完成行业方案调研、技术路径分析、同类产品对比等工作,最终基于模型输出的结构化调研报告进行技术决策。
提示词示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22项目背景与硬性约束
我正在开发一款企业级AI驱动的测试平台,技术选型已确定如下:
1. 大模型:接入 DeepSeek 在线大模型(文本生成)
2. 关系型数据库:PostgreSQL
3. 部署方式:前后端均在本地开发环境直接运行(暂不考虑容器化或云端部署)
业务核心目标
实现“自然语言提问 → 自然语言信息分析 → 智能可视化展示”的一站式体验,让测试人员通过对话即可完成复杂测试任务。
具体业务功能模块
系统需包含以下核心模块(常规管理平台风格,UI轻快明亮、富有科技感):
1. 权限与用户管理:基于RBAC模式的角色、用户、权限控制。
2. 测试项目管理:项目基本信息维护、模块划分、项目成员协作管理。
3. 测试用例管理:支持需求文档检索与智能分析,生成并管理测试用例与测试套件。
基于以上需求和约束,请为我进行详细的底层架构设计,重点回答以下四个问题:
1. 核心技术选型:实现该系统可以运用大模型领域的哪些核心技术(如RAG、Agent、微调、向量检索、多模态处理等)?各自的适用场景是什么?
2. Agent开发框架:目前有哪些热门且企业常用的Agent开发框架(需包含合适的Skills、MCP等组件)能够很好地满足该需求?请推荐并对比。
3. 开源项目参考:是否有架构类似或模块可复用的开源项目可以推荐?
4. 前后端技术栈:结合上述约束(DeepSeek、PostgreSQL、本地运行),前后端具体技术栈应如何设计?(请给出语言、框架、库及中间件建议)上述提示词主要适用于项目前期探索阶段,即业务功能边界与技术栈选型尚存不确定性时的架构调研。一旦业务需求与技术方案已明确锁定,则可直接基于该确定性信息进入PRD文档生成环节,无需重复探索性提示。
可调用多个主流大模型(如ChatGPT、DeepSeek、Qwen、豆包等)分别生成调研报告,并通过横向对比,择优选出最契合项目需求的模型或方案。
产品原型
是连接需求分析与视觉设计的关键环节,它将抽象的产品需求转化为可交互、可评审的界面模型,让团队和利益相关方在写代码之前就能“看到”并“体验”产品未来的样子。
做法:在产品原型设计环节,传统流程需在需求分析后由美工进行设计再交付开发。如今,借助AI设计工具,开发人员可直接通过自然语言生成高质量高保真产品原型。目前主流的方案有:
- Google Stitch:Google Labs推出的AI原生设计平台,支持通过自然语言描述生成多屏UI设计并产出生产级前端代码。
- Figma:行业标准的协作设计工具,其AI功能(如Figma Make、Figma Agent)同样支持通过自然语言生成和迭代高保真原型。
对于使用Claude Code的AI编程场景,还可通过Stitch Skills(遵循Agent Skills开放标准)和Stitch MCP将设计能力直接集成到开发工作流中,实现“设计→代码”的无缝衔接。
- Google Stitch地址:https://stitch.withgoogle.com/
- figma地址:https://www.figma.com/
- stitch-skills地址:https://github.com/google-labs-code/stitch-skills
- Stitch MCP 地址:https://stitch.withgoogle.com/docs/mcp/setup
视觉页面设计方案:用AI生成产品原型时,千万别只给功能描述,最好提前准备好视觉页面设计方案。不然你会发现,AI生成出来的页面跟你的预期差距还挺大的,来回调整特别费时间。把颜色、字体、间距这些视觉规范提前喂给AI,产出的质量会明显高一个档次。
推荐另一个产品原型的产品:https://open-design.ai/zh/
架构设计
结合大模型输出的需求分析与技术调研报告,我们综合评估并确定本项目整体技术架构如下:
前端交互层:采用React生态的Next.js框架实现用户界面与交互逻辑,UI风格遵循”轻快明亮、富有科技感”的设计基调,产品原型输出物将作为前端页面开发的核心视觉参考。
后端服务层:基于FastAPI框架提供RESTful API服务,结合Tortoise-ORM异步ORM框架完成数据持久化操作,确保高并发场景下的响应性能。
AI能力层:核心接入DeepSeek在线大模型,提供自然语言理解与推理能力;采用LangChain生态中的DeepAgents框架构建智能体(Agent),负责测试需求分析、用例生成、知识问答等复杂任务的流程编排与工具调用。
数据存储层:以PostgreSQL作为主数据库,存储项目管理、用户权限、用例信息等结构化业务数据;向量数据库(待选型,如Pgvector或Milvus)用于存储知识库的文本嵌入向量,支撑语义检索与RAG应用。
在具体开发实施中,我们将以Claude Code作为核心AI编程工具,向其输入以下结构化提示词,由Claude Code依据架构设计完成各模块的代码生成与集成:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23项目背景与硬性约束
我正在开发一款企业级AI驱动的测试平台,技术选型已确定如下:
1. 大模型:接入 DeepSeek 在线大模型(文本生成)
2. 关系型数据库:PostgreSQL
3. 部署方式:前后端均在本地开发环境直接运行(暂不考虑容器化或云端部署)
业务核心目标
实现“自然语言提问 → 自然语言信息分析 → 智能可视化展示”的一站式体验,让测试人员通过对话即可完成复杂测试任务。
具体业务功能模块
系统需包含以下核心模块(常规管理平台风格,UI轻快明亮、富有科技感):
1. 权限与用户管理:基于RBAC模式的角色、用户、权限控制。
2. 测试项目管理:项目基本信息维护、模块划分、项目成员协作管理。
3. 测试用例管理:支持需求文档检索与智能分析,生成并管理测试用例与测试套件。
既定技术栈:
1. 后端服务框架:FastAPI + Tortoise-ORM(异步框架)
2. AI智能体框架:LangChain 生态的 DeepAgents
3. 前端框架:React + Next.js(脚手架搭建)
4. 前端页面:基于产品原型进行界面实现与交互开发
基于上述需求进行系统模块规划需要说明的是,上述由Claude Code进行架构分析后,会生成一份初步的任务拆解清单(TODO List)。不过,这份清单的颗粒度通常较粗——每个待办项可能对应一个完整的功能模块(如“实现测试用例管理”),涉及多个API、数据模型和前端页面。
如果一次性执行全部任务,会面临以下风险:
- 上下文窗口过载,AI难以同时处理多个高耦合功能
- 模块间依赖关系未理清,生成的代码可能逻辑冲突
- 问题定位困难,一旦出错难以快速回滚或定位根因
因此,开发者需根据项目进度与开发节奏,主动对TODO List进行细化拆分,并按优先级分步执行,确保每次交付的功能点粒度适中、可独立验证。建议将大任务拆解为“单个API端点 + 对应数据模型 + 基础前端组件”的小粒度任务,每个任务完成后进行本地验证,再进入下一个周期。这种“小步快跑”的节奏,既能充分发挥Claude Code的代码生成效率,又能有效控制风险,保障代码质量与系统稳定性。
功能拆分
完成上述架构分析与模块划分后,可继续使用Claude Code将开发任务进一步拆解为可执行的Phase(阶段)。合理的阶段划分能够将庞大复杂的项目分解为一系列边界清晰、可独立验证的子任务,有效降低开发风险,避免因模块耦合过紧导致的集成困难。
参考提示词
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21请将上述系统开发任务进一步拆解为以下Phase,每个阶段完成后需进行本地验证,确认无误后再进入下一阶段:
Phase 1:项目基础框架搭建
- 初始化前后端项目结构(FastAPI + Next.js)
- 配置PostgreSQL数据库连接与Tortoise-ORM
- 配置DeepSeek API接入与DeepAgents基础环境
- 编写健康检查接口与前端测试页面,验证基础链路通畅
Phase 2:后端核心接口开发
- 基于模块拆分方案,优先开发用户认证与权限管理(RBAC)接口
- 依次完成项目管理、用例管理等核心业务接口
- 使用Postman或FastAPI自动生成的Swagger文档进行接口自测
Phase 3:前端UI开发与集成
- 基于产品原型图,使用Next.js + React开发前端页面
- 先使用Mock数据填充页面,确保UI交互逻辑完整
- 待后端接口就绪后,将Mock数据切换为真实API调用
Phase 4:前后端联调与全链路测试
- 完成前后端数据对接,验证所有业务功能流程
- 执行端到端测试,覆盖核心用户场景
- 修复联调中发现的问题,确保系统整体可用这是一种在软件工程实践中被广泛采用的稳健策略:先搭建项目骨架并打通基础链路,再开发后端核心接口,随后在前端页面中接入真实数据,最后完成全链路联调与验收。按照这种分层推进、逐步集成的方式开展研发,能够有效降低耦合风险,确保每一阶段的产出物都是可验证、可回滚的,整体开发过程更加稳定可控。
任务管理
针对大型项目的研发工作,高效的团队协作与规范化的项目管理是保障开发进度、提升协作效率的关键,推荐一款专业的项目管理工具Linear,官方登录地址为:https://linear.app/login ,Linear是一款免费的在线项目管理平台,能够适配团队协作开发的各类管理需求,助力大型项目的任务拆解、进度追踪与团队协同。
Linear平台展示介绍
Linear map server:https://linear.app/docs/mcp,安装MCP服务后,可进行对AI编程工具进行使用
Linear API keys:Settings → API 或 Personal API keys
如何使用,参考提示词
1 | 请使用Linear MCP工具在Jean's team中添加一个test的todo任务 |
基于Rules构建AI管理项目的工作流
我们日常标准的研发流程为:领取开发任务 —> 编写代码 —> 本地自测与验证 —> 提交代码直GitHub仓库,同时同步更新Linear中的任务状态。
为了将这套规范、完整的流程固化为自动化、可复用的协同工作流,我们可以借助AI编辑器的Rules规则配置功能,实现编码、提交、任务状态管理的一体化联动。我们以Claude Code为例: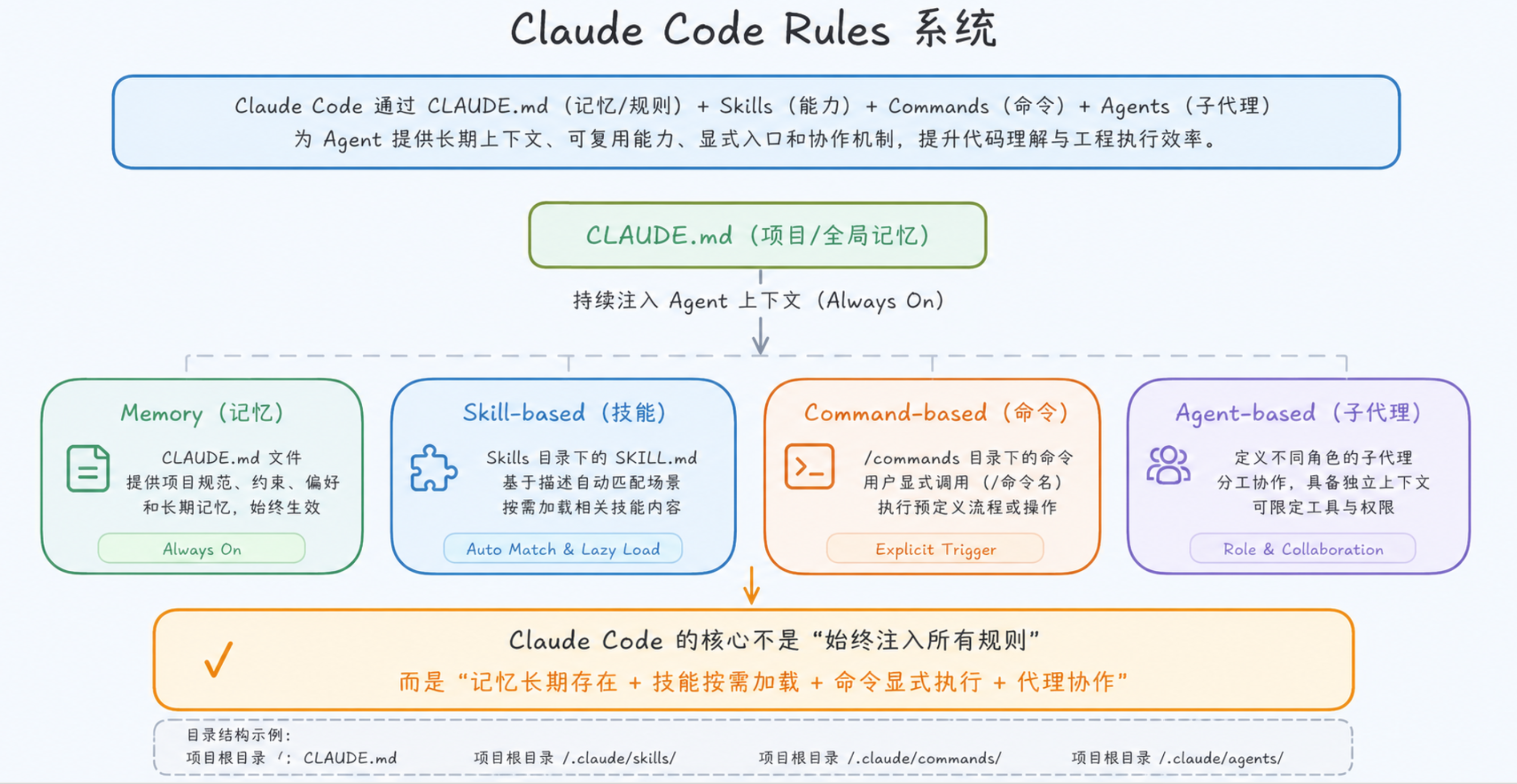
1 | project/ |
设计思想:
- CLAUDE.md → 定义原则(What)
- Skill → 定义流程(How)
- Command → 定义入口(Trigger)
- Agent → 定义角色(Who)
Claude Code中Rule机制(注:AI编辑器的Rules机制存在差异,可根据自己的习惯进行详细查找使用)
1 | Claude Code 工作机制 |
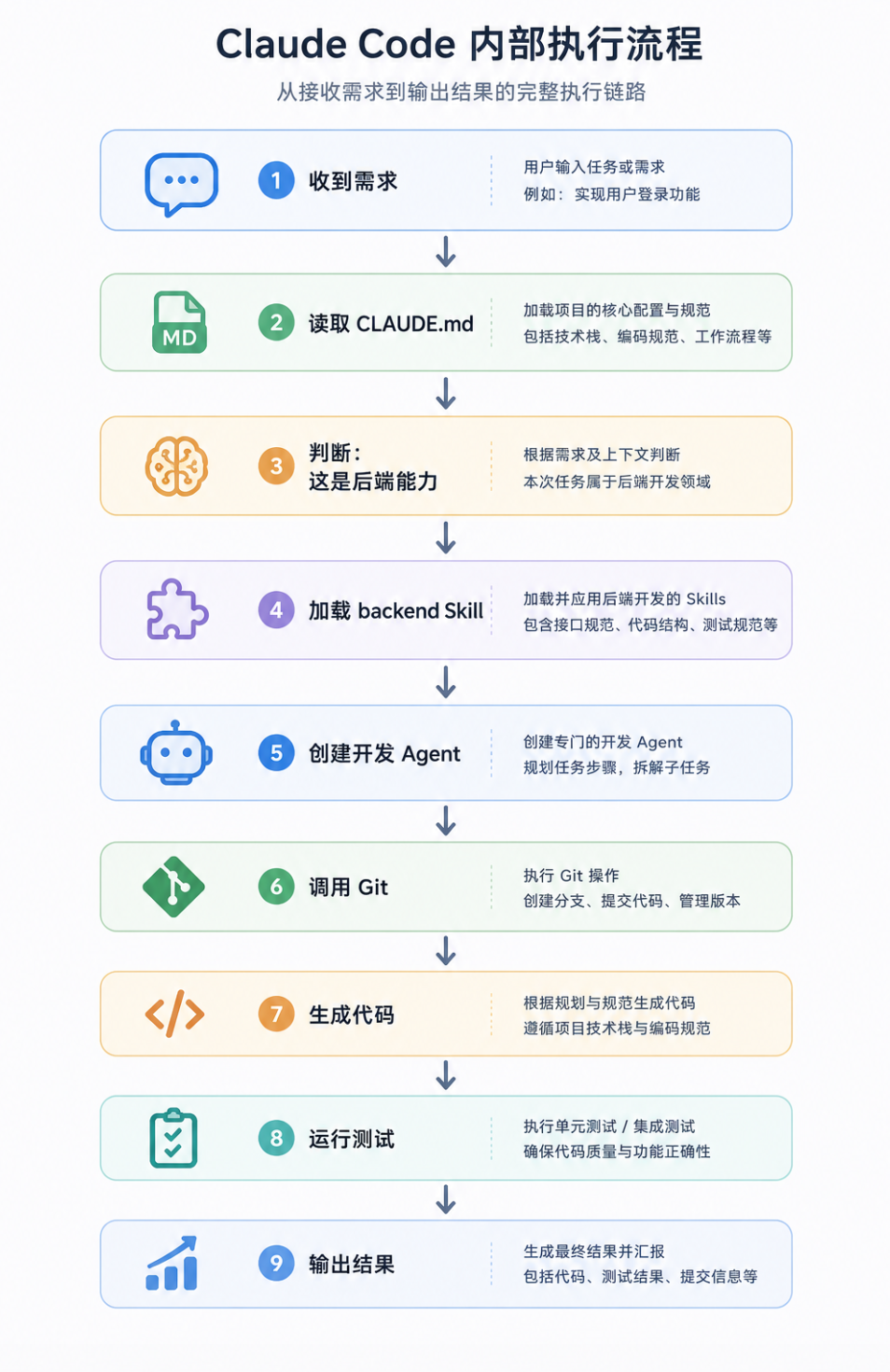
推荐的项目目录结构示例
1 | ai-testing-platform/ |
代码托管
完成项目初始化后,下一步就是将代码纳入版本控制系统(Version Control System, VCS) 的管理,并托管至GitHub平台。
为什么要使用Git?
在软件开发中,代码作为核心产物,在整个生命周期中持续迭代——新需求不断合入,缺陷修复持续提交。如果没有版本控制,我们只能靠手动复制文件来备份(如myCode_v1.js、myCode_final.js……),这种方式既容易出错又不可靠。Git作为目前最流行的分布式版本控制系统,正是为了解决这些问题而诞生的。
与SVN等集中式版本控制系统不同,Git采用分布式架构——每个开发者的本地机器上都拥有代码仓库的完整副本,包含全部历史记录、标签和分支信息。这意味着即使断网或中央服务器宕机,你依然可以离线提交、本地回退,待网络恢复后再同步到远程仓库。Git将版本管理的主动权真正交到了开发者手中。
Git的另一大核心优势在于其强大的分支管理能力。创建和销毁分支成本极低,切换速度极快,这使得团队可以并行开发多个功能而互不干扰。分支间的合并与追溯也极为高效,为复杂的协作场景提供了坚实基础。
此外,Git通过哈希加密保证数据的完整性,防止恶意篡改;代码分布存储在每台客户端,天然具备异地容灾能力。
为什么选择GitHub?
Git本身是版本控制引擎,而GitHub则是在此基础上提供代码托管服务与协作工具的平台。作为全球最大的开发者社区和开源软件的事实标准,GitHub的价值已超越单纯的代码存放地,成为开发者协作网络和技术趋势的风向标。
将项目托管在GitHub,意味着:
- 版本可追溯:每一次变更都被完整记录,随时可以回退到任意历史版本;
- 协作更高效:团队成员可以贡献代码、发起审查、通过Pull Request进行受控合并;
- 代码更安全:云端存储自动备份,即使本地设备出现故障,代码也不会丢失;
- 过程更透明:团队成员可以清晰看到项目进展,满足“巴士测试”——即便某位成员暂时无法参与,其他人也能无缝接手。
在Vibe Coding的语境下,代码托管的意义尤为突出。AI辅助生成的代码迭代频繁,如果没有版本控制作为“安全网”,一次失误的修改就可能让整个项目陷入混乱。而有了Git和GitHub的保障,每一次AI的代码变更都可以被追踪、审查和回退,让“沉浸式编程”真正变得可控、可持续。
在AI驱动的开发工作流中,代码仓库的版本管理同样可以实现智能化。借助GitHub MCP(Model Context Protocol)Server,我们可以将Claude Code与GitHub平台直接打通,让AI助手通过自然语言对话完成仓库管理、PR操作、CI/CD监控等任务。
GitHub MCP Server是GitHub官方推出的MCP服务,支持远程(Streamable HTTP)和本地(Docker)两种部署方式。对于Claude Code用户,官方提供了完整的安装指南。以下是具体的配置步骤:
获取GitHub Personal Access Token(PAT),在GitHub平台生成用于MCP认证的访问令牌:
- 访问 GitHub Personal Access Token创建页面
- 设置Token名称(便于识别,如
claude-mcp-github) - 选择过期时间(建议根据项目周期设定)
- Repository access 选择 All repositories(如需访问所有仓库)
- Permissions 设置:
- Administration:
Read and write - Contents:
Read and write
- Administration:
- 点击创建,务必立即保存生成的令牌(页面关闭后无法再次查看)
安装GitHub MCP Server
在终端(非Claude Code命令行内)执行以下命令
1
claude mcp add-json github '{"type":"http","url":"https://api.githubcopilot.com/mcp","headers":{"Authorization":"Bearer YOUR_GITHUB_PAT"}}'
- 将
YOUR_GITHUB_PAT替换为第一步生成的令牌即可。
- 将
注意:
版本说明:
claude mcp add-json命令适用于Claude Code 2.1.1及以上版本。若使用旧版本或遇到Invalid input错误,可使用以下传统命令格式:1
claude mcp add --transport http github --url https://api.githubcopilot.com/mcp --header "Authorization: Bearer YOUR_GITHUB_PAT"
可选参数 ——
--scope:指定配置的存储范围:local(默认):仅当前项目可用project:通过.mcp.json文件在项目内共享user:跨所有项目全局可用
示例(全局生效):
1
claude mcp add-json github '{"type":"http","url":"https://api.githubcopilot.com/mcp","headers":{"Authorization":"Bearer YOUR_GITHUB_PAT"}}' --scope user
验证安装
- 重启Claude Code
- 在Claude Code中输入
/mcp命令,查看已安装的MCP Server列表 - 若列表中出现
github服务,即表示安装成功
任务开发
完成上述所有准备工作后,项目正式进入核心环节——任务开发。前面我们完成了需求分析、架构设计、功能拆分和代码托管,这些本质上都是在为这一阶段铺路。现在,是时候让Claude Code真正“写代码”了。
在之前的“功能拆分”环节,我们已经将项目拆解为四个Phase:
| Phase | 内容 | 核心目标 |
|---|---|---|
| Phase 1 | 项目基础框架搭建 | 打通前后端基础链路,确保开发环境可用 |
| Phase 2 | 后端核心接口开发 | 完成RBAC权限及核心业务接口 |
| Phase 3 | 前端UI开发与集成 | 基于原型实现界面,从Mock切换到真实数据 |
| Phase 4 | 前后端联调与全链路测试 | 验证完整业务流程,修复集成问题 |
每个Phase内部,还需要进一步拆解为更小的开发任务(建议每个任务不超过2-3个API或1-2个前端页面),每个任务完成后进行本地验证,确认无误后再进入下一个任务。这种“小步快跑”的节奏,既能充分发挥Claude Code的代码生成效率,又能有效控制风险——即便某个任务出现问题,影响范围也可控,回滚成本极低。
输入给Claude Code的提示词应包含:
- 明确的任务目标:本次要完成什么功能(如“实现用户注册接口”)
- 技术约束与规范:遵循什么框架、什么编码规范(如“使用FastAPI + Tortoise-ORM”)
- 参考上下文:相关的数据模型设计、接口文档、原型图等
- 验收标准:如何判断任务完成(如“通过Swagger测试成功”)
提示词模板
1 | 请基于以下技术栈完成 [任务描述] 的开发: |
代码审查与质量保障
AI生成的代码虽然高效,但并不保证100%正确或符合项目规范。因此,建议在每个Phase结束后进行代码审查:
- 功能验证:运行接口测试或前端页面操作,确认功能正常工作
- 代码走查:检查代码风格是否符合项目规范,是否存在潜在的性能或安全问题
- 及时修正:发现问题立即让Claude Code修正,不要积压到联调阶段
持续集成与版本管理
在开发过程中,建议保持高频的代码提交节奏:
- 每完成一个子任务(如一个API端点或一个前端页面),提交一次代码
- 每完成一个Phase,推送一次代码到GitHub远程仓库
- 提交信息规范:用简洁清晰的英文或中文说明本次提交内容(如
feat: add user registration API或fix: resolve login authentication bug)
Claude Code通过GitHub MCP可以自动完成这些操作,例如:
- “将当前所有变更提交到本地仓库,提交信息为:feat: complete user login API”
- “将本地提交推送到远程仓库main分支”