LangChain的简介
LangChain是基于大型语言模型(LLM)应用程序的开源框架。它提供了一套工具和接口,简化了LLM应用的开发流程,使开发者能够更高效地构建复杂的、数据感知的AI应用,LangChain 的出现填补了 LLM 工程化的空白,让开发者能快速构建生产级应用(如客服机器人、数据分析工具),而无需从零实现底层交互逻辑。
1 | 理解:LangChain ≈ 大模型的“编排中间件”,让你可以像用 FastApi 写 Web 一样,快速写出一个智能体系统。 |
LangChain的核心价值
Langchain解决了大模型应用开发中的三大痛点:
- 连接外部世界:让模型能够调用工具、访问数据和外部系统交互
- 结构化开发:提供标准话组织和工作流,加速开发过程
- 可扩展性:支持多种模型、工具和集成方式,灵活适应不同场景
LangChian 的发展历史
鉴于 AI 领域不断变化的步伐,LangChain 也随时间演变。以下是 LangChain 多年来如何随着使用 LLM 构建应用的意义而变化的简要时间线
| 时间 | 版本 / 事件 | 描述 |
|---|---|---|
| 2022-10-24 | v0.0.1 发布 | LangChain 首次以 Python 包发布。包含两个核心组件:① LLM 抽象;② 链(Chain),用于构建如 RAG 的预定义步骤。名称来源于“Language + Chain”。 |
| 2022-12 | 第一个通用智能体 | 基于 ReAct(推理 + 行动)论文的通用 Agent 加入 LangChain。通过 LLM 生成表示工具调用的 JSON,并由框架解析后执行。 |
| 2023-01 | ChatCompletions 支持 | OpenAI 发布 ChatCompletions API,模型从字符串接口转为消息列表接口。LangChain 同步更新支持消息格式。 |
| 2023-01 | JS 版本发布 | LangChain 发布 JavaScript 版本,以满足前端/全栈开发者的 LLM 应用需求。 |
| 2023-02 | LangChain Inc. 成立 | LangChain 公司成立,使命为“让智能体无处不在”。开始构建围绕 LangChain 的完整生态。 |
| 2023-03 | Function Calling 支持 | OpenAI 发布函数调用(Function Calling),提供结构化的工具调用方式。LangChain 更新为优先使用函数调用,而不再依赖 JSON 解析。 |
| 2023-06 | LangSmith 发布 | LangSmith(闭源)发布,用于智能体可观测性与评估。LangChain 也随之更新为可与 LangSmith 深度集成。 |
| 2024-01 | v0.1.0 发布 | LangChain 首个非 0.0.x 稳定版本。行业进入生产化阶段,框架更重视 API 稳定性。 |
| 2024-02 | LangGraph 开源 | 引入用于智能体编排的底层状态机框架,补足 LangChain 仅支持高级接口的不足。新增支持:流式、持久执行、短期记忆、人机协作等。 |
| 2024-06 | 700+ 集成 | LangChain 生态超过 700 个集成。核心集成迁移到独立包或 langchain-community,使核心库更轻量。 |
| 2024-10 | LangGraph 成为主流编排方式 | 构建 AI 应用的首选方式从 LangChain Chains/Agents 迁移到 LangGraph。大多数旧接口被标记为弃用,并提供迁移指南。LangGraph 仍提供一个高级 Agent 抽象,与早期 ReAct Agent 相兼容。 |
| 2025-04 | 消息格式支持多模态 | 模型 API 全面多模态化:支持输入文件、图像、视频。LangChain 更新消息格式以标准化多模态输入。 |
| 2025-10-20 | v1.0.0 发布 | 两大变化:① 所有 Chains 和 Agents 全部被统一为一个基于 LangGraph 的高级 Agent 抽象;旧版接口迁移到 langchain-classic;② 标准化消息内容格式,以兼容推理块、引用、服务器端工具调用等更复杂的输出格式。 |
从Langchain的发展来看,版本改动有很大的变化,新版本对于之前版本废弃了很多功能,使得Langchain的功能更集中于智能体的开发,因此由此看出学习框架还是以官方文档为主,也要随时准备新内容的替换
LangChain v1.2核心特性
1. 简单易用的 Agent 框架
LangChain v1.2 提供了预构建的智能体(Agent)架构,让你能快速搭建具备工具调用能力的 AI 助手:
- 支持多种工具自动选择和调用,AI 可以根据任务自动判断该用什么工具。
- 内置会话记忆和持久化能力,能记住之前的对话内容,实现多轮交互。
- 提供可定制的系统提示和行为引导,你可以灵活定义 AI 的角色和行为规则。
2. 丰富的模型集成
它能轻松对接市面上主流的大语言模型,无需关心底层实现细节:
- OpenAI、Anthropic、Google 等主流模型即插即用,开箱即用。
- 采用统一的接口设计,切换不同模型时不需要修改代码结构,降低了迁移成本。
- 支持模型参数精细化配置,可以根据需求调整温度(temperature)、最大 tokens 等参数。
3. 强大的工具生态
丰富的工具集让 AI 可以执行各种实际任务,与外部世界交互:
- 内置网络搜索、计算器、文件操作等常用工具,满足基础需求。
- 提供自定义工具接口,可以轻松扩展新能力,接入你自己的业务系统。
- 支持工具参数自动推断和验证,减少手动配置的工作量。
4. 基于 LangGraph 的可靠执行
LangChain v1.2 的 Agent 构建在 LangGraph 之上,提供了更可靠的执行保障:
- 持久化执行状态,支持断点续传,即使任务中断也能从上次位置继续执行。
- 具备流式输出能力,可以像 ChatGPT 一样逐字返回结果,提升用户体验。
- 提供可控的延迟和执行流程,让你能更好地管理和监控 Agent 的运行。
LangChain环境
官方文档:https://docs.langchain.com/oss/python/langchain/install
基本安装:
1 | pip install -U langchain |
注意:Python版本在3.10以上
快速开始-LangChain创建Agent
1 | from langchain.agents import create_agent |
使用invoke调用,查看下调用结果:
1 | {'messages': [HumanMessage(content='今天北京的天气怎么样', additional_kwargs={}, response_metadata={}, id='13db96a7-e210-4512-8085-c642faf499a6'), AIMessage(content='今天北京的天气情况如下: \n- **温度**:最高约 28°C,最低约 18°C,体感较为舒适。 \n- **天气**:白天晴朗,夜间多云,无降水。 \n- **风力**:微风,约 2-3 级,对出行影响较小。 \n- **空气质量**:良好(AQI 约 50-80),适合户外活动。 \n\n建议您根据温度变化适时增减衣物,享受秋日的好天气! 🌤️', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 107, 'prompt_tokens': 22, 'total_tokens': 129, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 22}, 'model_provider': 'openai', 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_eaab8d114b_prod0820_fp8_kvcache', 'id': '544f29e5-c12d-43b3-82f7-50e43fec1530', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--eb33f7b1-4d66-471a-b52a-13a064eda5cc-0', usage_metadata={'input_tokens': 22, 'output_tokens': 107, 'total_tokens': 129, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]} |
输出结果详解:
1. HumanMessage:用户的提问
这代表用户输入的原始内容。
content:用户的问题文本,这里是“今天北京的天气怎么样”。id:系统为这条消息生成的唯一标识符。
2. AIMessage:智能体的完整回应
这部分是核心,包含了AI的回答以及这次调用背后的大量元数据。
content:AI生成的自然语言回答,即关于北京天气的具体描述。id:此条AI消息的唯一标识符。additional_kwargs:一个额外参数字典,用于存储模型特有的返回信息。这里的{'refusal': None}表示模型没有拒绝回答。usage_metadata:令牌使用统计,这是API调用的计费依据。input_tokens: 22, 提示词消耗的令牌数。output_tokens: 107, 回答内容消耗的令牌数。total_tokens: 129, 总计令牌数。
response_metadata:本次调用的响应元数据,对于调试和日志记录非常关键。finish_reason:stop, 表示模型正常完成生成。其他可能值包括length(达到长度限制)或tool_calls(触发了工具调用)等。model_name:deepseek-chat, 显示实际使用的模型。token_usage: 与usage_metadata类似,更详细的令牌使用情况。
接下来我们使用stream调用直接输出结果:
1 | from langchain.agents import create_agent |
直接输出的内容
1 | <generator object Pregel.stream at 0xbb9809b90> |
使用stream方式直接输出的是一个生成器对象,本身是不包含完整的对象,需要通过循环输出其中的数据,输出的示例如下:
1 | for chunk in res: |
输出结果如下:
1 | {'model': {'messages': [AIMessage(content='北京今天(2024年7月18日)的天气情况如下: \n- **天气**:多云转晴 \n- **气温**:最高 33°C,最低 24°C \n- **风向风力**:南风 2-3级 \n- **空气质量**:轻度污染(AQI 约 110) \n\n建议白天注意防晒,早晚较舒适,适合户外活动。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 86, 'prompt_tokens': 22, 'total_tokens': 108, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 22}, 'model_provider': 'openai', 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_eaab8d114b_prod0820_fp8_kvcache', 'id': '84d237bb-7ebb-4f90-a604-e0cde829bcf2', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--71543f5c-b957-4b71-80ab-8853667ea061-0', usage_metadata={'input_tokens': 22, 'output_tokens': 86, 'total_tokens': 108, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]}} |
输出结果详解:
| 层级 | 键名 | 值 | 解释 |
|---|---|---|---|
| 最外层 | ‘model’ |
{...} |
这是关键!它表明这个数据块来自图中名为 ‘model’ 的节点。 在LangGraph中,每个节点(如LLM、工具、函数)执行后,都会以 {节点名: 输出} 的格式产生一个数据块。 |
| 第二层 | ‘messages’ |
[AIMessage(...)] |
model 节点的输出内容,是一个列表,其中包含一个 AIMessage 对象。这通常就是语言模型对用户问题的直接回答。 |
| 第三层 (AIMessage) | ‘content’ |
‘北京今天(2024...’ |
AI生成的实际文本内容,也就是最终呈现给用户的天气预报。 |
‘response_metadata’ |
{...} |
本次模型调用的详细元数据,是调试和分析的关键。 | |
‘usage_metadata’ |
{...} |
本次调用的令牌(Token)使用统计,用于计算API成本。输入22个Token,输出了86个,总计108个Token。 |
流式传输的核心特点与操作
flowchart TD
A[用户输入] --> B{图开始执行}
B --> C[节点A执行
(例如:工具调用)]
C --> D[产生第一个数据块
(chunk: ‘agent’)]
D --> E[节点B执行
(例如:模型推理)]
E --> F[产生第二个数据块
(chunk: ‘model’)]
F --> G[节点C执行...]
G --> H[图执行结束]
D & F -.-> I[❄️ 数据块实时输出
(for chunk in res)]
以上示例是没有带工具的,下面智能体带有工具,查看下调用的情况
1 | from langchain.agents import create_agent |
输出结果如下:
1 | {'messages': [HumanMessage(content='今天北京的天气怎么样', additional_kwargs={}, response_metadata={}, id='261af454-231e-4112-84ea-e24907aacd10'), AIMessage(content='我来帮您查询北京今天的天气情况。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 52, 'prompt_tokens': 362, 'total_tokens': 414, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 362}, 'model_provider': 'openai', 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_eaab8d114b_prod0820_fp8_kvcache', 'id': 'f1868170-e83a-4bfe-96a6-b0d26934a2d4', 'finish_reason': 'tool_calls', 'logprobs': None}, id='lc_run--801ef9cd-6378-4184-a106-868c07d0f7c1-0', tool_calls=[{'name': 'get_weather', 'args': {'city': '北京'}, 'id': 'call_00_QVYWKEhUjpmwBJk5p8W0UZ2a', 'type': 'tool_call'}], usage_metadata={'input_tokens': 362, 'output_tokens': 52, 'total_tokens': 414, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}), ToolMessage(content='晴,温度 25°C,湿度 45%', name='get_weather', id='d91e4515-cc08-45f2-b165-5759b887c378', tool_call_id='call_00_QVYWKEhUjpmwBJk5p8W0UZ2a'), AIMessage(content='根据查询结果,今天北京的天气情况如下:\n\n**天气状况**:晴\n**温度**:25°C\n**湿度**:45%\n\n今天北京天气晴朗,温度适中,湿度也比较舒适,是个不错的天气。建议您可以:\n- 外出时注意防晒,可以戴太阳镜或帽子\n- 这样的天气很适合户外活动,如散步、运动等\n- 早晚温差可能较大,建议携带薄外套\n\n空气质量信息暂时无法获取,如果您需要了解空气质量情况,建议查看专门的空气质量监测应用。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 109, 'prompt_tokens': 443, 'total_tokens': 552, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 384}, 'prompt_cache_hit_tokens': 384, 'prompt_cache_miss_tokens': 59}, 'model_provider': 'openai', 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_eaab8d114b_prod0820_fp8_kvcache', 'id': 'f94a1a62-2584-4cf8-aba2-b8f63b98c107', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--281eba53-839f-4718-8c67-b131e96a3d67-0', usage_metadata={'input_tokens': 443, 'output_tokens': 109, 'total_tokens': 552, 'input_token_details': {'cache_read': 384}, 'output_token_details': {}})]} |
输出结果详解
| 消息类型 | 内容摘要 | 关键字段与作用 | 在流程中的角色 |
|---|---|---|---|
| HumanMessage | 用户提问:“今天北京的天气怎么样” | content: 用户问题原文 |
触发对话 |
| AIMessage (1) | “我来帮您查询北京今天的天气情况。” | finish_reason: tool_calls tool_calls: 指定调用 get_weather 工具 |
决策与规划:模型决定调用工具 |
| ToolMessage | “晴,温度 25°C,湿度 45%” | content: 工具执行结果 tool_call_id: 关联到对应的工具调用 |
执行与反馈:工具执行并返回结果 |
| AIMessage (2) | 根据结果生成的完整、友好的天气报告 | finish_reason: stop |
整合与回答:模型整合信息,生成最终答案 |
- 开始:
HumanMessage代表用户输入。 - 第一轮模型推理:模型(第一个
AIMessage)没有直接猜测天气,而是分析出需要调用工具,并在tool_calls字段中声明要调用get_weather工具,参数为{"city": "北京"}。finish_reason为tool_calls明确表示停止是因为要调用工具。 - 工具执行:系统执行名为
get_weather的工具(可能是一个查询天气的API函数),并将结果(“晴,温度 25°C,湿度 45%”)包装成ToolMessage返回。tool_call_id是关联工具调用和结果的关键,必须与AIMessage中的调用ID(call_00...)一致。 - 第二轮模型推理:模型(第二个
AIMessage)收到ToolMessage后,将工具返回的原始数据整合成一段自然、友好的中文描述,并补充了生活建议。此时finish_reason为stop,表示正常结束。
这个输出完美演示了LangChain Agent的核心能力:理解问题、决定使用工具、执行工具、并基于结果生成回答。
Agent核心组件概览
flowchart TD
%% 定义全局样式
classDef coreComponent fill:#f0f8ff,stroke:#2196f3,stroke-width:2px,rounded:10px
classDef contextStyle fill:#f5fafe,stroke:#03a9f4,stroke-width:2px,rounded:10px
%% 上下文作为基础容器(居中核心)
subgraph Context["上下文 (Context)"]
direction TB
C1["用户信息/偏好"]
C2["会话状态/历史"]
C3["环境变量/配置"]
C4["临时数据存储"]
end
class Context contextStyle
%% 四大核心组件环绕上下文
subgraph LLM["语言模型 (LLM/Chat Model)"]
direction TB
L1["Claude/GPT/Gemini"]
L2["模型参数配置"]
L3["文本理解/生成"]
end
class LLM coreComponent
subgraph Tools["工具 (Tools)"]
direction TB
T1["预构建工具
(搜索/计算)"]
T2["自定义工具扩展"]
T3["工具自动选择器"]
end
class Tools coreComponent
subgraph Memory["记忆 (Memory)"]
direction TB
M1["短期会话记忆"]
M2["长期持久化记忆"]
M3["状态断点续传"]
end
class Memory coreComponent
subgraph Middleware["中间件 (Middleware)"]
direction TB
MW1["执行流程拦截"]
MW2["上下文管理控制"]
MW3["日志/监控/限流"]
end
class Middleware coreComponent
%% 组件关联关系(体现协作逻辑)
Context --> LLM
Context --> Tools
Context --> Memory
Context --> Middleware
LLM <--> Tools
LLM <--> Memory
Middleware -.拦截/管控.-> LLM
Middleware -.拦截/管控.-> Tools
1. 语言模型组件(LLM/Chat Model)
这是 Agent 的 “大脑”,负责核心的思考、推理和生成能力:
- LLM(大型语言模型):提供文本理解和生成能力。
- Chat Model(聊天模型):专门优化过对话交互的模型。
- 模型配置与参数:可调整温度(temperature)、最大 tokens 等,控制输出风格和随机性。
- 示例:Claude、GPT、Gemini 等主流大模型。
2. 工具组件(Tools)
这是 Agent 与外部世界交互的 “手脚”,让 AI 能执行实际任务:
- 预构建工具:开箱即用的工具,如搜索、计算器、API 调用等。
- 自定义工具:可以接入你自己的业务系统或第三方服务。
- 工具选择器:让 Agent 能根据任务自动判断该使用哪个工具。
- 示例:网络搜索、数学计算、调用天气 API 等。
3. 记忆组件(Memory)
这是 Agent 的 “记忆中枢”,负责存储和检索历史信息:
- 短期记忆:保存当前会话的上下文,用于多轮对话。
- 长期记忆:持久化存储重要信息,可跨会话使用。
- 状态持久化:支持断点续传,任务中断后可恢复执行。
- 示例:InMemorySaver(内存存储)、Redis(分布式存储)等。
4. 中间件组件(Middleware)
这是 LangChain 1.0 的核心功能,是一组可插拔的钩子函数,嵌入到 Agent 的执行流程中:
- Agent 执行流程拦截:可以在 Agent 思考、调用工具等关键步骤前 / 后插入自定义逻辑。
- 上下文管理与控制:统一管理和修改 Agent 运行时的上下文信息。
- 执行步骤自定义处理:对每个执行步骤进行日志记录、监控或修改。
- 生产环境落地支持:提供日志、监控、限流等企业级能力。
- 示例:Agent Middleware、Model Request Middleware 等。
5. 上下文(Context)
这是 Agent 运行时的 “环境容器”,提供所需的环境信息和状态管理:
- 用户信息与偏好:存储用户的个人信息、偏好设置。
- 会话状态与历史:管理当前会话的状态和历史交互记录。
- 环境变量与配置:传递 API 密钥、服务地址等配置信息。
- 临时数据存储:用于存储执行过程中的临时数据。
- 示例:自定义 Context 类、会话 ID、请求上下文等。
LangChain v1.2与相关技术的关系
LangChain v1.2 与 LangGraph:核心依赖关系
定位:LangGraph 是 LangChain 的底层执行引擎,负责 Agent 的状态管理和流程控制。
核心能力:
- 执行层分离:LangChain 负责定义 Agent “做什么”(任务逻辑),LangGraph 负责 “如何做”(执行流程),让状态管理和错误处理更可靠。
- 图结构执行:把 Agent 执行流程抽象成有向图,节点是操作,边是状态转换,能支持复杂的控制流。
- 持久化能力:支持 Agent 状态持久化,实现跨会话的记忆和状态恢复。
- 并发执行:支持并行处理多个任务或工具调用,提升效率。
- 一句话总结:LangChain 定义 “做什么”,LangGraph 负责 “如何做”,两者协同提供强大灵活的 Agent 开发框架。
LangChain v1.2 与 DeepAgents:生态系统扩展
定位:DeepAgents 是基于 LangChain 构建的高级 Agent 框架,专注于复杂任务分解和多 Agent 协作。
核心能力:
- 上层抽象:在 LangChain 基础上提供更高层级的抽象,简化复杂 Agent 系统的开发。
- 多 Agent 协作:专注于多 Agent 系统的设计和协作模式,支持角色分工和任务分配。
- 复杂任务分解:提供任务自动分解和规划能力,把大任务拆成可管理的子任务。
- 专业领域优化:针对科学研究、数据分析等特定领域,提供预构建的 Agent 模板和工具集。
- 一句话总结:DeepAgents 是 LangChain 的专业化扩展,适合构建更复杂、协作型的 AI 系统,而 LangChain 为它提供基础架构支持。
flowchart TD
subgraph "顶层:高级抽象层"
direction TB
DeepAgents["DeepAgents"]
DA1["高级Agent框架,构建于LangChain之上"]
DA2["提供多Agent协作与复杂任务分解能力"]
DA3["专注于专业化领域的Agent系统开发"]
end
subgraph "中层:中间组件层"
direction TB
LangChain["LangChain"]
LC1["核心Agent组件定义与工具集成框架"]
LC2["提供中间件扩展机制和统一接口标准"]
LC3["依赖LangGraph提供底层执行和状态管理"]
end
subgraph "底层:执行引擎层"
direction TB
LangGraph["LangGraph"]
LG1["基于图结构的执行引擎,负责流程控制"]
LG2["提供可靠的状态管理和错误处理机制"]
LG3["支持并发执行和跨会话状态持久化"]
end
%% 层级关系箭头
DeepAgents -->|"基于扩展"| LangChain
LangChain -->|"依赖执行"| LangGraph
%% 样式定义
classDef top fill:#f9e79f,stroke:#f39c12,stroke-width:2px,rounded:10px
classDef middle fill:#d6eaf8,stroke:#3498db,stroke-width:2px,rounded:10px
classDef bottom fill:#d5f5e3,stroke:#27ae60,stroke-width:2px,rounded:10px
class DeepAgents top
class LangChain middle
class LangGraph bottom
架构说明
- 底层:执行引擎层(LangGraph):作为整个系统的 “动力核心”,基于图结构提供可靠的流程控制、状态管理和并发执行能力,是所有上层逻辑的运行基础。
- 中层:中间组件层(LangChain):作为核心开发框架,负责定义 Agent 组件、集成工具集,并提供统一接口与扩展机制,同时依赖 LangGraph 保障执行可靠性。
- 顶层:高级抽象层(DeepAgents):作为专业化扩展框架,在 LangChain 基础上提供多 Agent 协作、任务分解等高级能力,专注于复杂场景和专业领域的 Agent 系统开发。
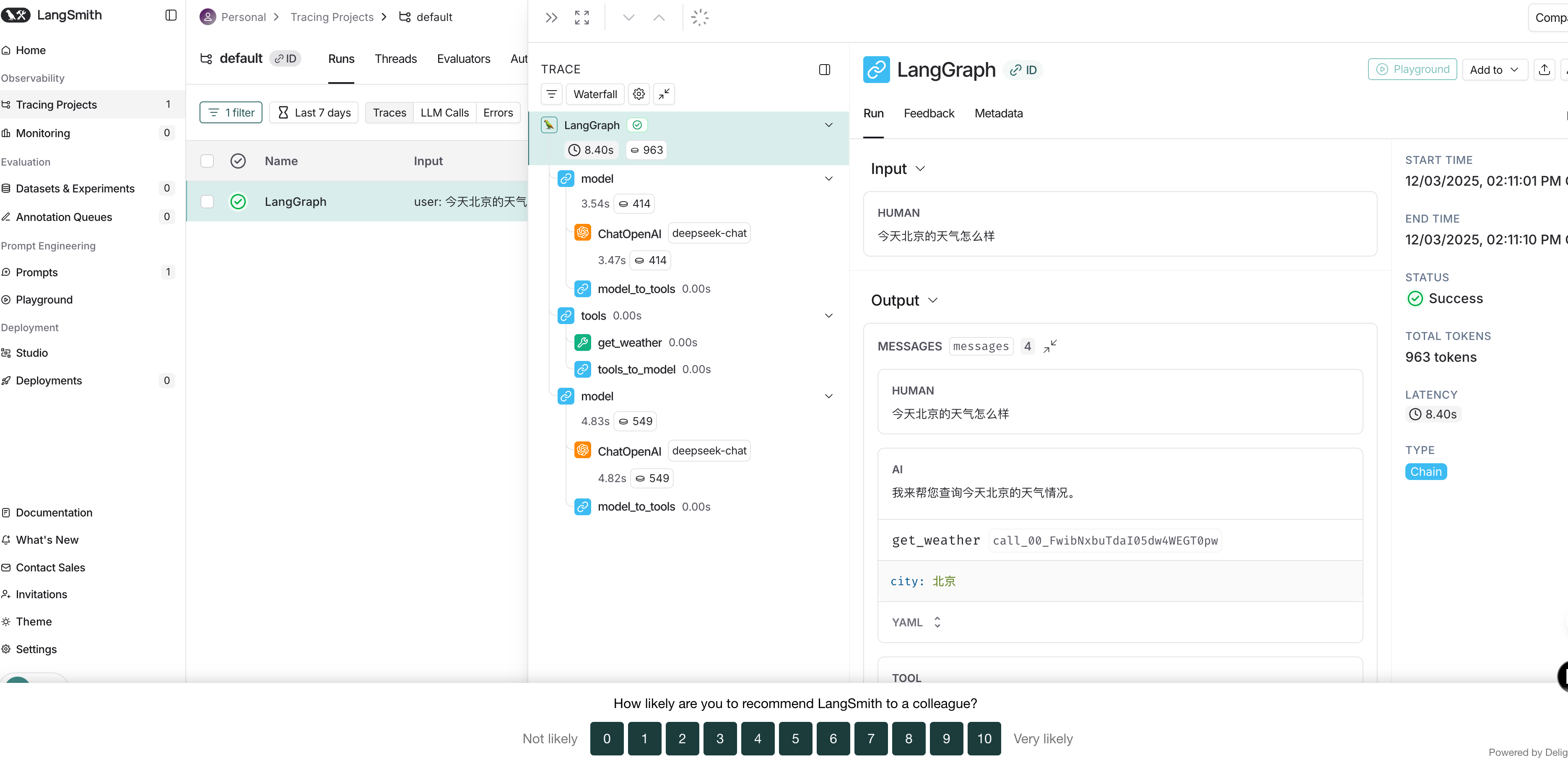
LangSmith接入
LangSmith 提供开发、调试和部署 LLM 应用的工具。它帮助你在一个地方追踪请求、评估输出、测试提示并管理部署。 LangSmith 不受框架限制,所以你可以和 LangChain 的开源库 langchain 和 langgraph 一起使用,也可以不使用。 先在本地进行原型开发,然后通过集成监控和评估进入生产,构建更可靠的人工智能系统。
使用:
创建一个账户:注册地址( smith.langchain.com 无需信用卡)。你可以用 Google、GitHub 或电子邮件登录 。
创建一个API密钥:进入设置页面 → API 密钥 → 创建 API 密钥 。复制密钥并安全保存。
安装依赖
1
pip install langsmith
在项目的.env 中配置 langsmith 的 API_KEY
1
2
3
4LANGSMITH_TRACING=true
LANGSMITH_ENDPOINT=https://api.smith.langchain.com
LANGSMITH_API_KEY="<your-langsmith-api-key>"
LANGSMITH_WORKSPACE_ID="<your-workspace-id>"完成以上配置即可,再次执行智能体,则在LangSmith上看到执行监控到的信息