Python里使用[]创建一个列表。容器类型的数据进行运算和操作,生成新的列表最搞笑的办法——列表生成式。
列表生成式,优雅、简洁,下面盘点在工作中主要使用案例和场景。
案例一:数据在运算
实现对每个元素的乘方操作后,利用列表生成式返回一个新的列表。
1
2
3
4
5a = range(0, 11)
# 利用列表生成式创建列表
b = [ x**2 for x in a ]
b
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
将数值型的元素列表,转换为字符串类型的列表。
1
2
3
4a = range(0, 10)
b = [ str(i) for i in a ]
b
['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']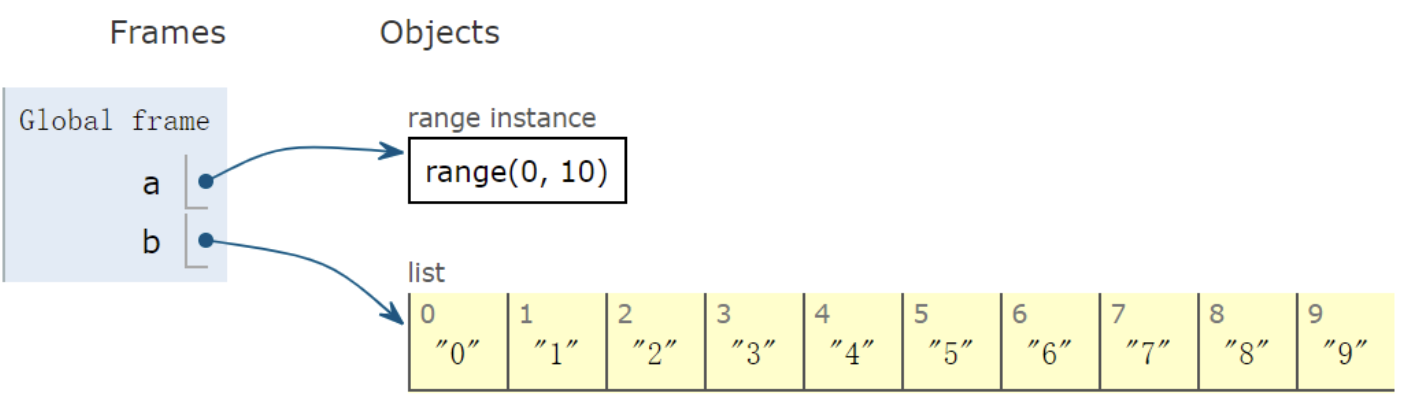
案例二:一串随机数
生成10个0到1的随机浮点数,保留小数点后两位
1
2
3
4from random import random
a = [ round(random(), 2) for _ in range(10) ]
a
[0.84, 0.76, 0.42, 0.26, 0.51, 0.4, 0.78, 0.3, 0.48, 0.58]
生成10个0到10的满足均匀分布的浮点数,保留小数点后两位
1
2
3
4from random import uniform
a = [ round(uniform(0, 10), 2) for _ in range(10) ]
a
[4.43, 5.12, 1.03, 4.67, 0.45, 6.39, 6.71, 8.41, 0.12, 8.13]
案例三:if和嵌套for
对一个列表里面的数据筛选,只计算
[0, 11)中偶数的平方1
2
3
4a = range(11)
c = [ x**2 for x in a if x%2==0 ]
c
[0, 4, 16, 36, 64, 100]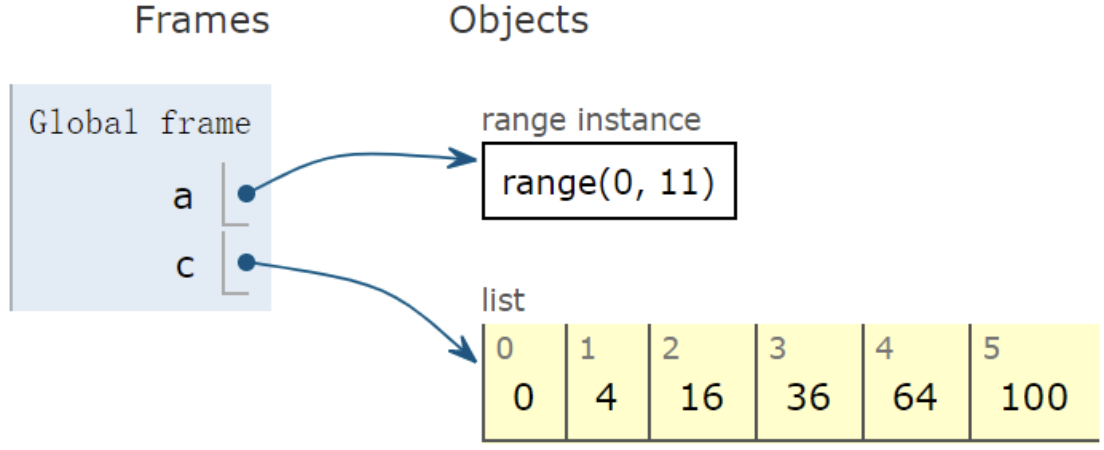
列表生成式中嵌套for,一行代码生成99乘法表的45个元素
1
2
3
4
5a = [ i*j for i in range(10) for j in range(1, i+1) ]
a
[1, 2, 4, 3, 6, 9, 4, 8, 12, 16, 5, 10, 15, 20, 25, 6, 12, 18, 24, 30, 36, 7, 14, 21, 28, 35, 42, 49, 8, 16, 24, 32, 40, 48, 56, 64, 9, 18, 27, 36, 45, 54, 63, 72, 81]
len(a)
45
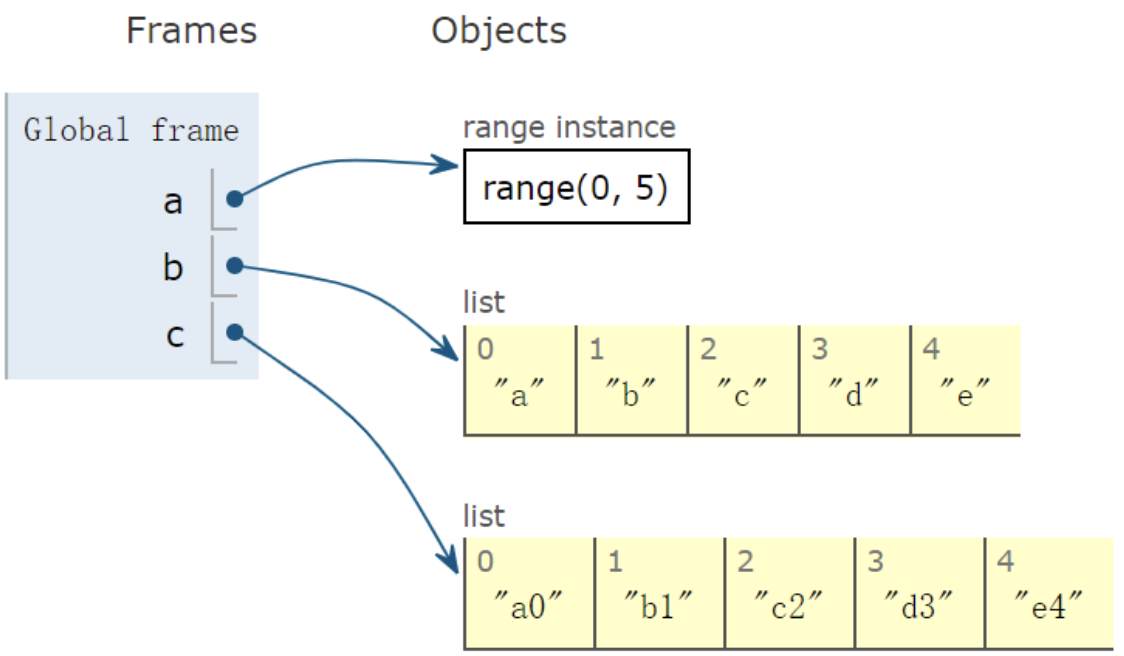
案例四:zip和列表
将两个列表组合成一个新的列表
1 | a = range(5) |
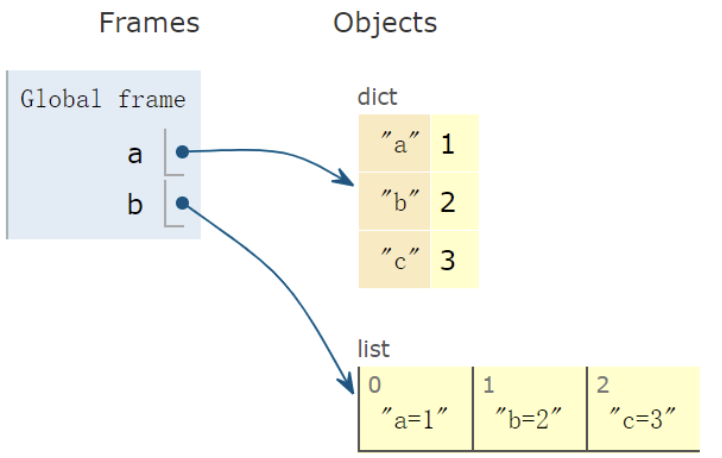
案例五:打印键值对
1 | a = { 'a': 1, 'b': 2, 'c': 3 } |
注意:Python属于强类型语言,注意数据的类型
案例六:文件列表
查询目录下所有文件
1
2
3
4import os
a = [ d for d in os.listdir('.')]
a
['scaffolds', 'db.json', 'source', 'node_modules', '_config.butterfly.yml', 'yarn.lock', 'public', '.gitignore', 'package-lock.json', 'package.json', '_config.yml', '.github', '_config.landscape.yml', '.deploy_git', 'themes']
只查找出文件夹(目录)
1
2
3dirs = [ d for d in os.listdir('.') if os.path.isdir(d) ]
dirs
['scaffolds', 'source', 'node_modules', 'public', '.github', '.deploy_git', 'themes']
只查找出文件
1
2
3files = [ d for d in os.listdir('.') if os.path.isfile(d) ]
files
['db.json', '_config.butterfly.yml', 'yarn.lock', '.gitignore', 'package-lock.json', 'package.json', '_config.yml', '_config.landscape.yml']
案例七:转为小写
1 | a = [ 'Hello', 'World', '2022python' ] |
注意:Python的列表中的元素是可以不同数据类型的,如果按以上方法写是会报错的,例如:
1 | a = [ 'Hello', 'World', 2022, 'Python' ] |
上面操作出现int对象没有方法lower的问题,因此需要将元素转化为str后再操作:
1 | [ str(w).lower() for w in a ] |
更友好的做法,使用 isinstance,判断元素是否为 str 类型,如果是,再调用 lower 做转化:
1 | [ w.lower() for w in a if isinstance(w, str) ] |
案例八:保留唯一值
1 | def filter_non_unique(lst): |
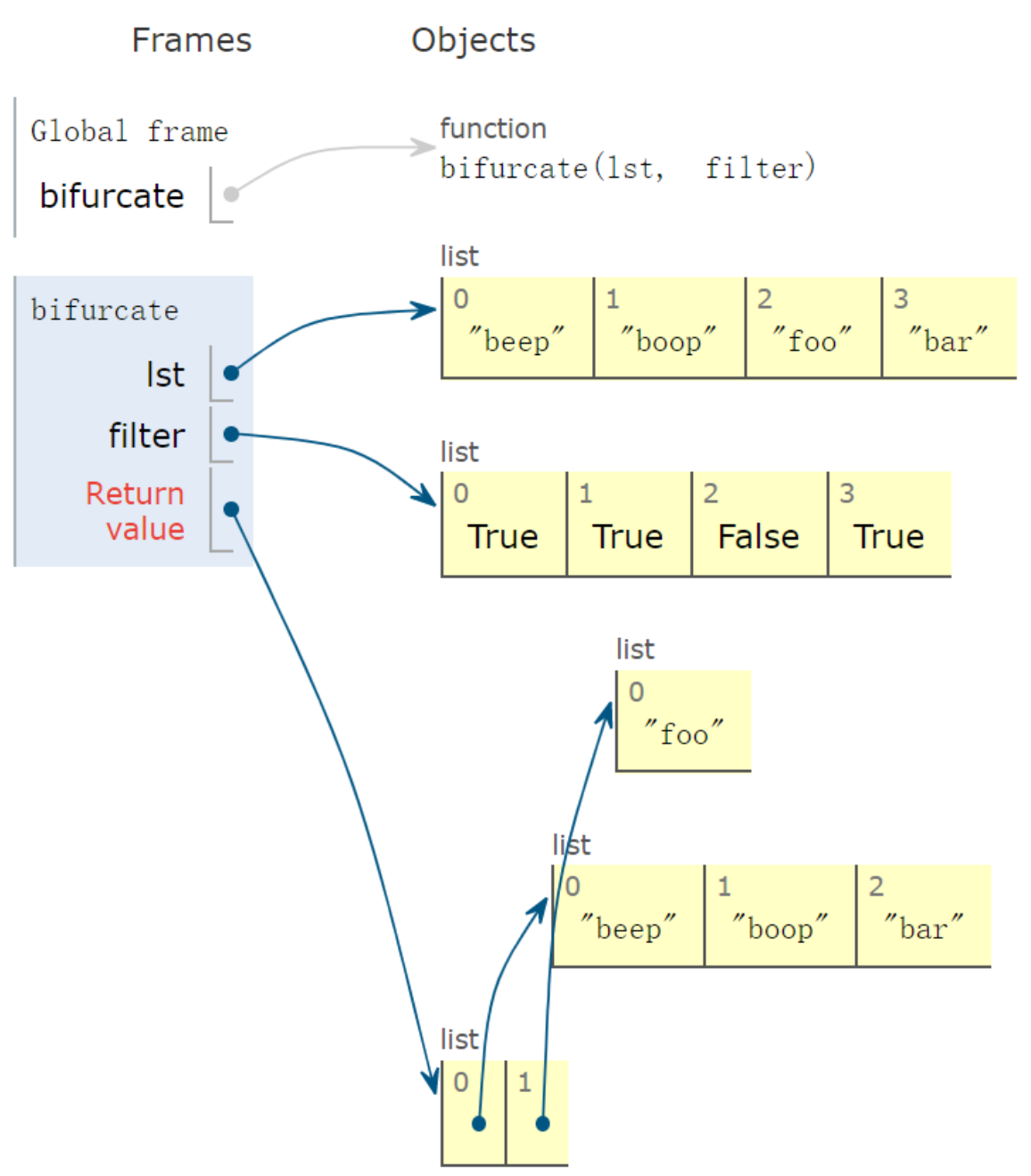
案例九:筛选分组
1 | def bifurcate(lst, filter): |
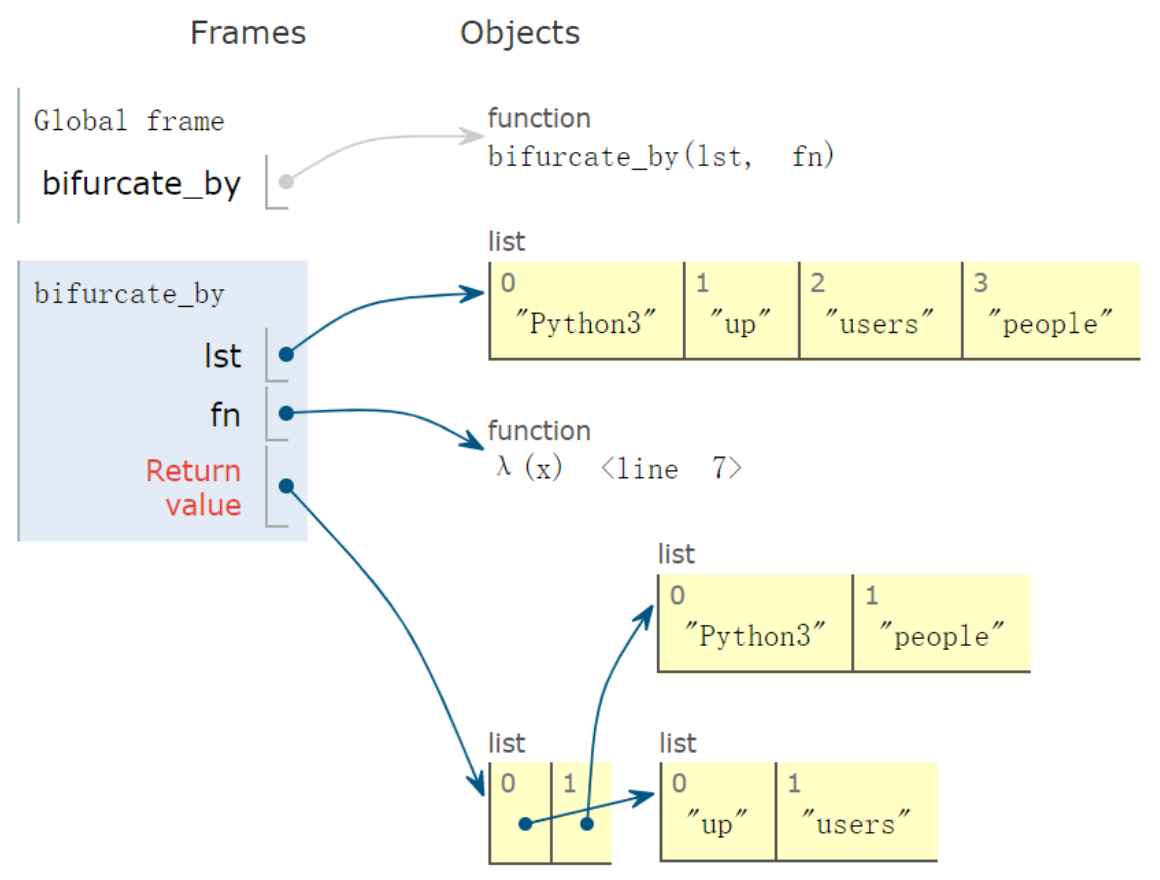
案例十:函数分组
1 | def bifurcate_by(lst, fn): |
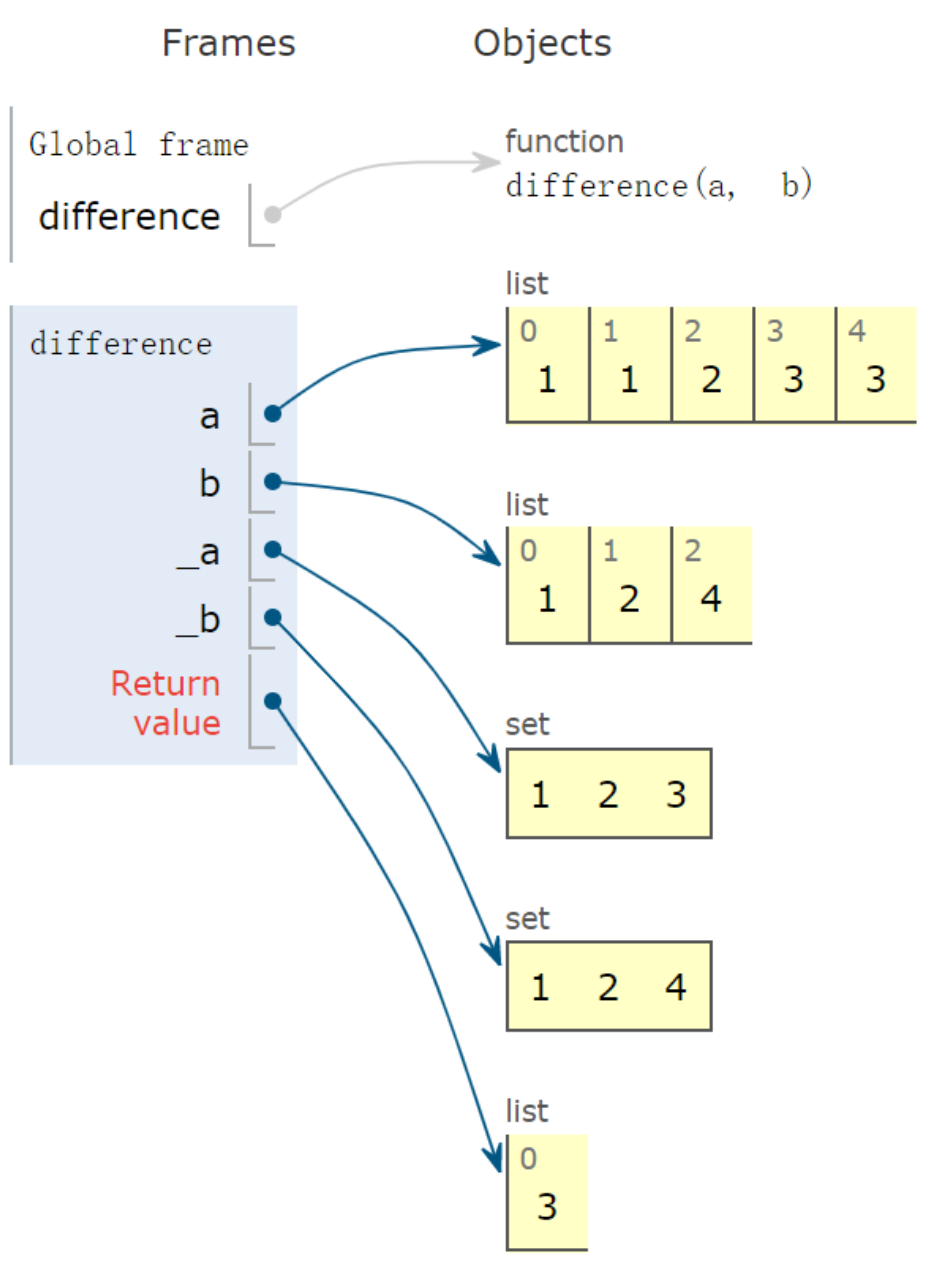
案例十一:差集
1 | def difference(a, b): |
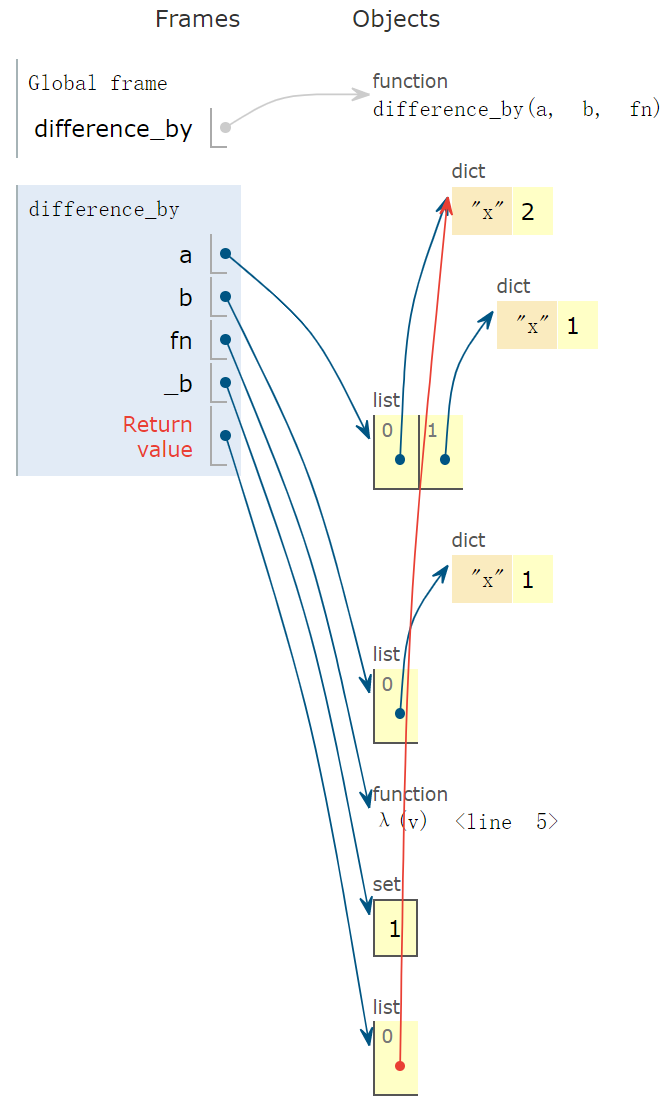
案例十二:函数差集
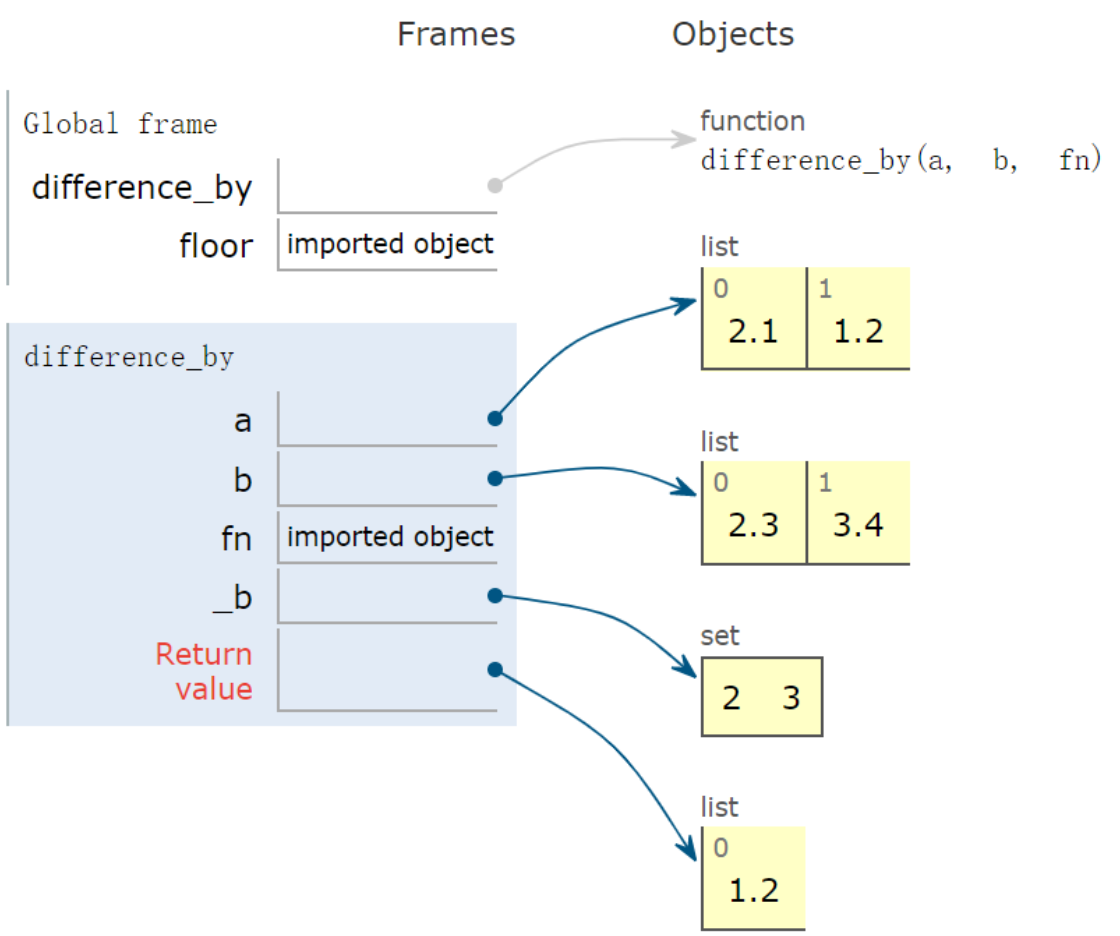
列表a、b中元素经过fn映射后,返回在a不在b中的元素。
1 | def difference_by(a, b, fn): |
列表元素为单个元素
1 | from math import floor |
列表元素为字典
1 | difference_by([{ 'x': 2}, { 'x': 1 }], [{ 'x': 1}], lambda v: v['x']) |