我们先了解下Python文件IO的常用操作:
- 涉及文件读写操作
- 获取文件后缀名
- pil修改后缀名
- 获取文件修改时间
- 压缩文件
- 加密文件等常用操作
案例一:文件读操作
文件读、写操作比较常见。但是在读取文件时,先要判断文件是否存在。处理如下:
- 若文件存在,则进行读取
- 若文件不存在,抛出文件不存在异常
1 | import os |
试着读取一个文件:
1 | # 读取文件 |
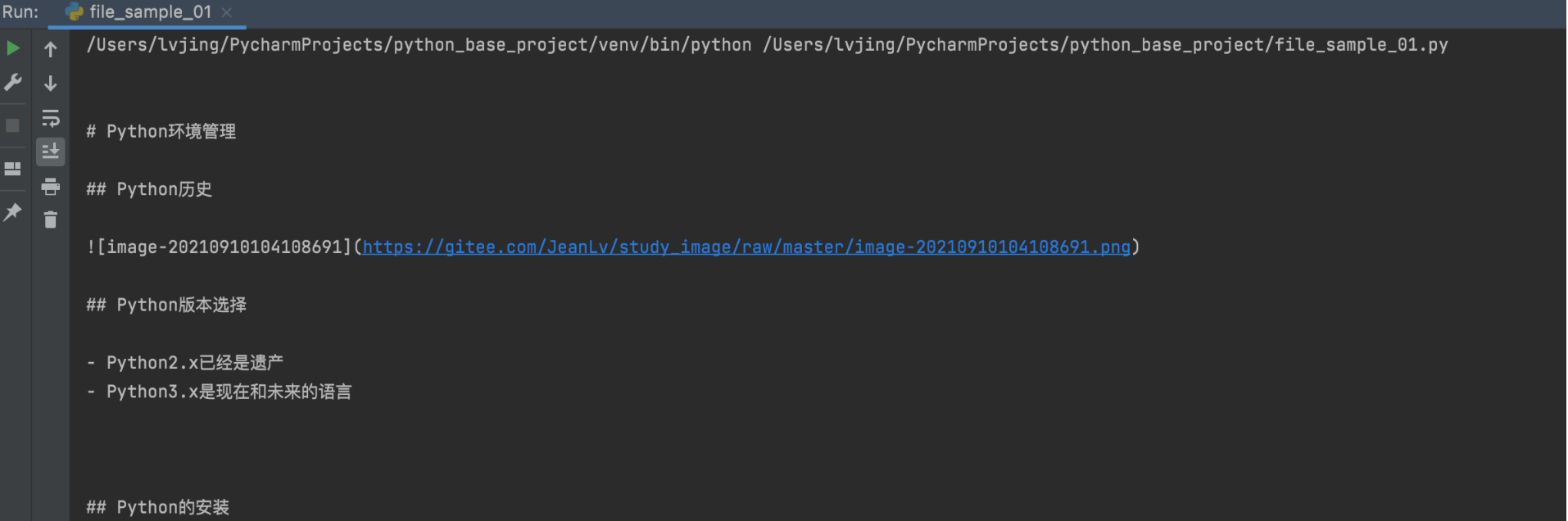
可以正常读取文件内容了。但是,有时候我们在读取问题件,会报如下的错误:
1 | UnicodeDecodeError: 'gbk' codec can't decode byte 0xaa in position 46: illegal multibyte sequence |
从提示上看,是编码问题。open 函数打开文件,默认编码格式与平台系统有关,鉴于此,有必要在 open 时为参数 encoding 赋值,一般采用 UTF-8:
1 | import os |
代码打开文件的编码确认为 UTF-8 后,还需要确认,磁盘中这个文件编码格式也为 UTF-8。
上面代码中,文件在open后,一定要close掉,否在资源被打开,没有正常关闭,再次操作会报错的,这种写法有些繁琐,还容易出错。借助with语法,同时实现open和close功能功能,这是跟常用的方法。
1 | import os |
案例二:文件按行读取
- read函数一次读取整个文件
- readlines函数按行一次读取整个文件
文件数据量小时,使用上面两个函数时没有问题的,但是,文件数据量大师,read或readlines一次读取整个文件,内存就会面临重大挑战。
- readline函数一次读取文件一行内容,能解决大文件读取内存溢出问题
文件a.txt内容如下:
1 | Hey, Python |
如下,读取文件 a.txt,r+ 表示读写模式。代码块实现:
- 每次读取一行。
- 选择正则 split 分词,注意观察 a.txt,单词间有的一个空格,有的多个。这些情况,实际工作中确实也会遇到。
- 使用 defaultdict 统计单词出现频次。
- 按照频次从大到小降序。
1 | import re |
运行结果:
1 | /Users/lvjing/PycharmProjects/python_base_project/venv/bin/python /Users/lvjing/PycharmProjects/python_base_project/file_sample_02.py |
案例三:文件写操作
文件写操作时,首先也需要判断写入的文件路径是否存在。若不存在,通过mkdir创建出路径;否则,直接写入文件。
1 | import os |
以上这段代码思路:
- 路径不存在,创建路径
- 写文件
- 读取同一文件
- 验证写入到文件的内容是否正确
代码执行
1 | print(write_to_file('/Users/lvjing/Documents', 'b.txt')) |
执行结果
1 | /Users/lvjing/PycharmProjects/python_base_project/venv/bin/python /Users/lvjing/PycharmProjects/python_base_project/file_sample_03.py |
我们可以看下到指定的目录,多了一个b.txt的文件,打开查看,是我们写入的内容。
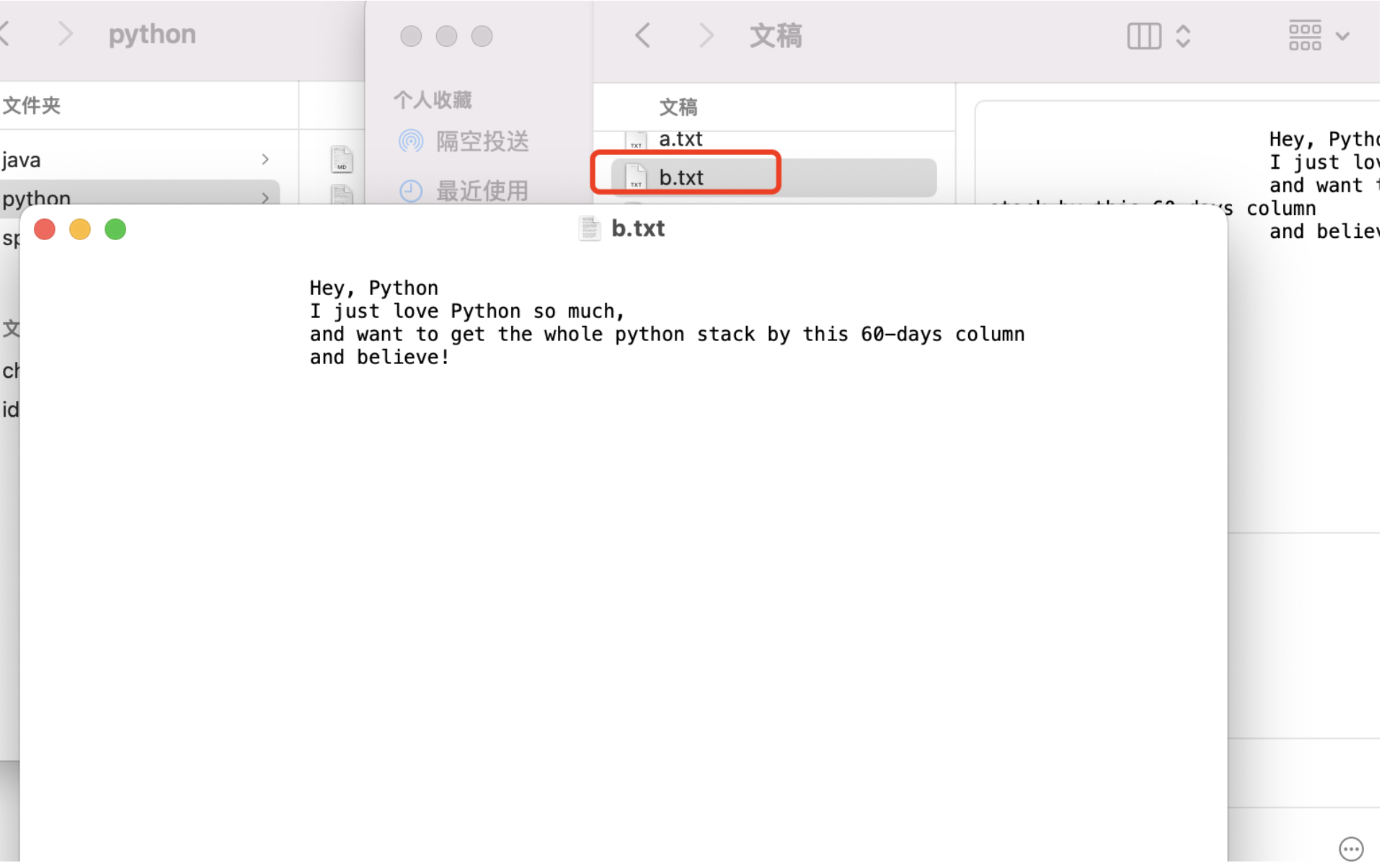
案例四:获取文件名
有时拿到一个文件名时,文件名称是带有路径。这时,使用 os.path、split 方法实现路径和文件的分离。
1 | import os |
运行结果
1 | /Users/lvjing/PycharmProjects/python_base_project/venv/bin/python /Users/lvjing/PycharmProjects/python_base_project/file_sample_04.py |
案例五:获取后缀名
如何优雅地获取文件后缀名?os.path 模块,splitext 能够优雅地提取文件后缀。
1 | import os |
运行结果
1 | /Users/lvjing/PycharmProjects/python_base_project/venv/bin/python /Users/lvjing/PycharmProjects/python_base_project/file_sample_05.py |
案例六:获取后缀名的文件
1 | import os |
案例七:批量修改后缀
将工作目录 work_dir 下所有后缀名为 old_ext 的文件,修改为 new_ext。通过此案例,同时掌握 argparse 模块。
后缀名批量修改,实现思路:
- 遍历目录下的所有文件
- 拿到此文件的后缀名
- 如果后缀名命名为old_ext,rename重命名
代码实现:
1 | # 定义脚本参数 |
运行结果
1 | (venv) lvjing@lvjingdeMacBook-Pro python_base_project % python3 file_sample_07.py './data' 'py' 'txt' |
查看目录,已经完成文件后缀名的替换
案例八:XLS批量转换成XLSX
此案例是上面案例的特殊情况,实现仅对XLS文件后缀修改
1 | import os |
运行结果:
1 | /Users/lvjing/PycharmProjects/python_base_project/venv/bin/python /Users/lvjing/PycharmProjects/python_base_project/file_sample_08.py |
案例九:批量获取文件修改时间
os.walk生成文件树结构os.path.getmtime返回文件的最后一次修改时间
1 | import os |
运行结果
1 | /Users/lvjing/PycharmProjects/python_base_project/venv/bin/python /Users/lvjing/PycharmProjects/python_base_project/file_sample_09.py |
案例十:批量压缩文件
需要导入zipfile模块,压缩和解压
1 | import os |
案例十一:32位文件加密
hashlib 模块支持多种文件的加密策略。本案例使用 MD5 加密策略:
1 | import hashlib |
案例十二:定制文件不同行
比较两个文件在哪些行内容不同,返回这些行的编号,行号编号从 1 开始。
1 | def statLineCnt(statfile): |
a.txt文件内容
1 | hello world!!!! |
b.txt文件内容
1 | hello world!!!! |
执行结果:
1 | /Users/lvjing/PycharmProjects/python_base_project/venv/bin/python /Users/lvjing/PycharmProjects/python_base_project/file_sample_12.py |