update
实际使用字典时,需要批量插入键值对到已有字典中,使用 update 方法实现批量插入。
已有字典中批量插入键值对:
1
2
3
4
5
6
7
8
9
10
11
12
13
| >>> d = {'a': 1, 'b': 2}
>>> d.update({'c': 3, 'd': 4, 'e': 5})
>>> d
{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}
>>> d = {'a': 1, 'b': 2}
>>> d.update([('c', 3), ('d', 4), ('e', 5)])
>>> d
{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}
>>> d.update([('c', 3), ('d', 4)], e=5)
>>> d
{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}
|
setdefault
如果仅当字典中不存在某个键值对时,才插入到字典中;如果存在,不必插入(也就不会修改键值对)。
这种场景,使用字典自带方法 setdefault:
1
2
3
4
5
6
7
8
9
10
11
12
13
| >>> d = {'a': 1, 'b': 2}
>>> r = d.setdefault('c', 3)
>>> r
3
>>> d
{'a': 1, 'b': 2, 'c': 3}
>>> r = d.setdefault('c', 33)
>>> r
3
>>> d
{'a': 1, 'b': 2, 'c': 3}
|
字典并集
先来看这个函数 f,为了好理解,显示的给出参数类型、返回值类型(但这些不是必须的)。
1
2
3
4
5
6
7
| >>> def f(d:dict) -> dict:
... return {**d}
...
>>> f({'a':1, 'b':2})
{'a': 1, 'b': 2}
>>> f({'a':1, 'b':2, 'c':3})
{'a': 1, 'b': 2, 'c': 3}
|
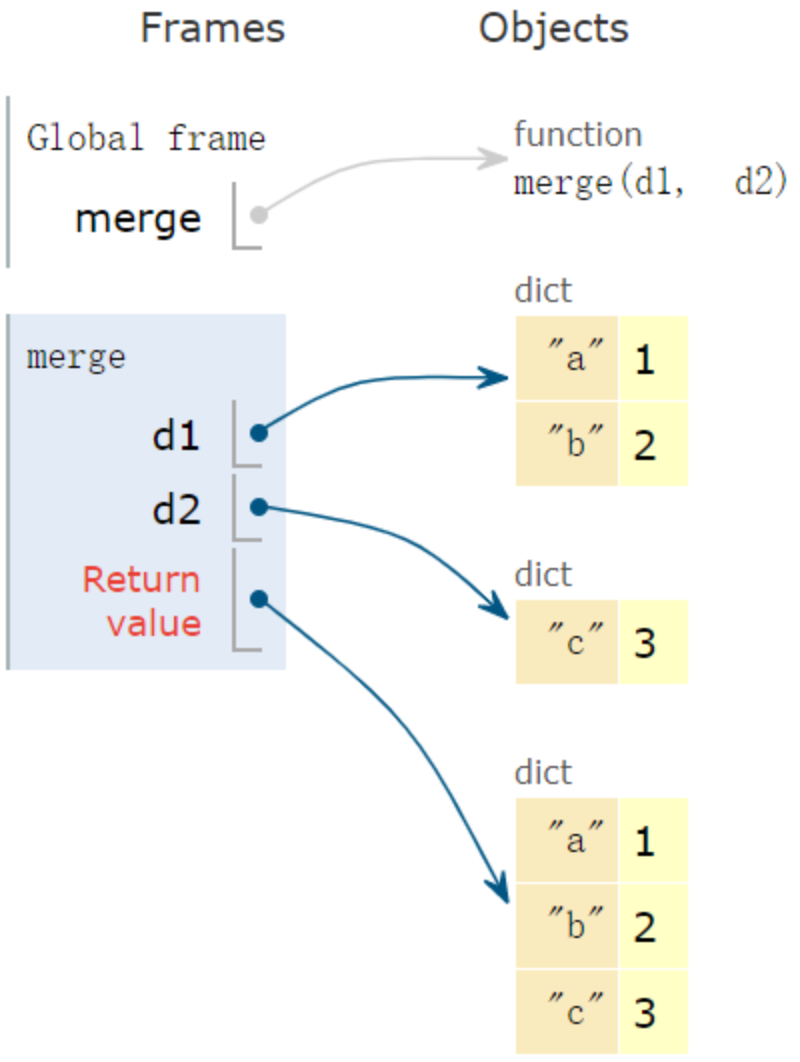
下面实现一个字典合并,并返回一个新字典功能:
1
2
3
4
5
| >>> def merge(d1, d2):
... return {**d1, **d2}
...
>>> merge({'a': 1, 'b': 2}, {'c': 3})
{'a': 1, 'b': 2, 'c': 3}
|
以下为示意图:
字典差
1
2
3
4
5
| >>> def difference(d1, d2):
... return dict([(k, v) for k, v in d1.items() if k not in d2])
...
>>> difference({'a': 1, 'b': 2, 'c': 3}, {'b': 2})
{'a': 1, 'c': 3}
|
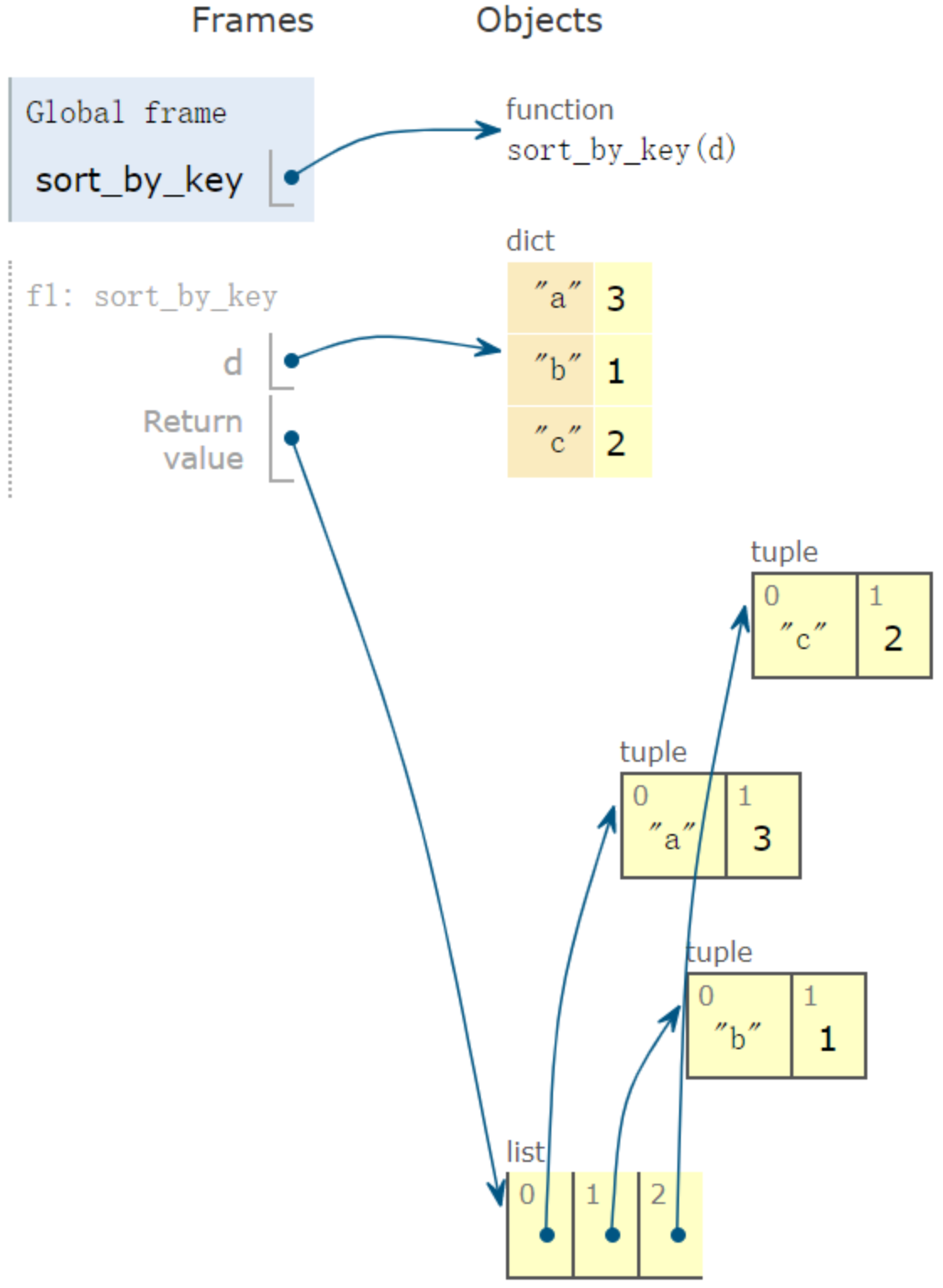
按键排序
1
2
3
4
5
| >>> def sort_by_key(d):
... return sorted(d.items(), key=lambda x: x[0])
...
>>> sort_by_key({'a': 3, 'b': 1, 'c': 2})
[('a', 3), ('b', 1), ('c', 2)]
|
sorted 函数返回列表,元素为 tuple:
按值排序
与按照键排序原理相同,按照值排序时,key 函数定义为按值(x[1])比较。
为什么是x[1]?d.items()返回元素为(key, value)示例:dict_items([('a', 3), ('b', 1), ('c', 2)])的可迭代类型(Iterable),key函数的参数x便是元素(key, value),所以x[1]取到字典的值。
1
2
3
4
5
| >>> def sort_by_key(d):
... return sorted(d.items(), key=lambda x: x[0])
...
>>> sort_by_key({'a': 3, 'b': 1, 'c': 2})
[('a', 3), ('b', 1), ('c', 2)]
|
最大键
通过 keys 拿到所有键,获取最大键,返回 (最大键,值) 的元组
1
2
3
4
5
6
7
8
| >>> def max_key(d):
... if len(d) == 0:
... return []
... max_key = max(d.keys())
... return (max_key, d[max_key])
...
>>> max_key({'a': 3, 'c': 3, 'b': 2})
('c', 3)
|
最大字典值
最大值的字典,可能有多对:
1
2
3
4
5
6
7
8
| >>> def max_value(d):
... if len(d) == 0:
... return []
... max_val = max(d.values())
... return [(key, max_val) for key in d if d[key] == max_val]
...
>>> max_value({'a': 3, 'b': 3, 'c': 2})
[('a', 3), ('b', 3)]
|
集合最值
找出集合中的最大、最小值,并装到元组中返回:
1
2
3
4
5
| >>> def max_min(s):
... return (max(s), min(s))
...
>>> max_min({1, 3, 5, 7})
(7, 1)
|
单字符串
若组成字符串的所有字符仅出现一次,则被称为单字符串。
1
2
3
4
5
6
7
| >>> def single(s):
... return len(set(s)) == len(s)
...
>>> single('love_python')
False
>>> single('love')
True
|
更长集合
key 函数定义为按照元素长度比较大小,找到更长的集合:
1
2
3
4
5
| >>> def longer(s1, s2):
... return max(s1, s2, key=lambda x: len(x))
...
>>> longer({1, 3, 5, 7}, {1, 5, 7})
{1, 3, 5, 7}
|
重复最多
在两个列表中,找出重叠次数最多的元素。默认只返回一个。
解决思路:
- 求两个列表的交集
- 遍历交集列表中的每一个元素,
min(元素在列表 1 次数, 元素在列表 2 次数),就是此元素的重叠次数
- 求出最大的重叠次数
1
2
3
4
5
6
7
| >>> def max_overlap(lst1, lst2):
... overlap = set(lst1).intersection(lst2)
... ox = [(x, min(lst1.count(x), lst2.count(x))) for x in overlap]
... return max(ox, key=lambda x: x[1])
...
>>> max_overlap([1, 2, 2, 2, 3, 3], [2, 2, 3, 2, 2, 3])
(2, 3)
|
top-n键
找出字典前 n 个最大值,对应的键。
实现思路:
- 导入 Python 内置模块 heapq 中的 nlargest 函数,获取字典中的前 n 个最大值。
- key 函数定义按值比较大小
1
2
3
4
5
6
| >>> from heapq import nlargest
>>> def top_n_dict(d, n):
... return nlargest(n, d, key=lambda k: d[k])
...
>>> top_n_dict({'a': 10, 'b': 8, 'c': 9, 'd': 10}, 3)
['a', 'd', 'c']
|
一键对多值字典
一键对多个值的实现方法 1,按照常规思路,循序渐进:
1
2
3
4
5
6
7
8
9
| >>> d = {}
>>> lst = [(1, 'apple'), (2, 'orange'), (1, 'computer')]
>>> for k, v in lst:
... if k not in d:
... d[k] = []
... d[k].append(v)
...
>>> d
{1: ['apple', 'computer'], 2: ['orange']}
|
以上方法,有一处 if 判断,确认 k 是不是已经在返回结果字典 d 中。不是很优雅!
可以使用 collections 模块中的 defaultdict,它能创建属于某个类型的自带初始值的字典。使用起来更加方便:
1
2
3
4
5
6
7
8
| >>> from collections import defaultdict
>>> d = defaultdict(list)
>>> lst = [(1, 'apple'), (2, 'orange'), (1, 'computer')]
>>> for k, v in lst:
... d[k].append(v)
...
>>> d
defaultdict(<class 'list'>, {1: ['apple', 'computer'], 2: ['orange']})
|
逻辑上合并字典
之前在案例:字典并集 中已经介绍了合并字典的方法:
1
2
3
4
5
| >>> dic1 = {'x': 1, 'y': 2}
>>> dic2 = {'y': 3, 'z': 4}
>>> merged = {**dic1, ** dic2}
>>> merged
{'x': 1, 'y': 3, 'z': 4}
|
修改 merged['x']=10,dic1 中的 x 值不变,merged 是重新生成的一个“新字典”。
1
2
3
4
5
| >>> merged['x'] = 10
>>> merged
{'x': 10, 'y': 3, 'z': 4}
>>> dic1
{'x': 1, 'y': 2}
|
但是,collections 模块中的 ChainMap 函数却不同,它在内部创建了一个容纳这些字典的列表。使用 ChainMap 合并字典,修改 merged['x']=10 后,dic1 中的 x 值改变。
如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
| >>> from collections import ChainMap
>>> dic1 = {'x': 1, 'y': 2}
>>> dic2 = {'y': 3, 'z': 4}
>>> merged = ChainMap(dic1, dic2)
>>> merged
ChainMap({'x': 1, 'y': 2}, {'y': 3, 'z': 4})
>>> merged['x'] = 10
>>> merged
ChainMap({'x': 10, 'y': 2}, {'y': 3, 'z': 4})
>>> dic1
{'x': 10, 'y': 2}
|