判断 list 内有无重复元素 is_duplicated,使用 list 封装的 count 方法,依次判断每个元素 x 在 list 内的出现次数。
如果大于 1,则立即返回 True,表示有重复。
如果完成遍历后,函数没返回,表明 list 内没有重复元素,返回 False。
1 2 3 4 5 6 7 8 9 10 11 def is_duplicated (lst ): for x in lst: if lst.count(x) > 1 : return True return False a = [1 , -2 , 3 , 4 , 1 , 2 ] print (is_duplicated(a))
执行结果:
以上的方法不简洁,也可以借助set的特点进行判断更方便:
1 2 3 4 5 6 def is_duplicated (lst ): return len (lst) != len (set (lst)) a = [1 , -2 , 3 , 4 , 1 , 2 ] print (is_duplicated(a))
列表反转 一行代码实现列表反转,非常简洁。
[::-1],这是切片的操作。[::-1] 生成逆向索引(负号表示逆向),步长为 1 的切片。
1 2 3 4 5 6 7 def reverse (lst ): return lst[::-1 ] r = reverse([1 , -2 , 3 , 4 , 1 , 2 ]) print (r)
执行结果:
找出列表中的所有重复元素 遍历列表,如果出现次数大于 1,且不在返回列表 ret 中,则添加到 ret 中。
满足 x not in ret,则表明 x 不在列表中。
1 2 3 4 5 6 7 8 9 10 11 12 def find_duplicate (lst ): ret = [] for x in lst: if lst.count(x) > 1 and x not in ret: ret.append(x) return ret r = find_duplicate([1 , 2 , 3 , 4 , 3 , 2 ]) print (r)
执行结果:
斐波那契数列 斐波那契数列第一、二个元素都为 1,第三个元素等于前两个元素和,依次类推。
普通实现版本 1 2 3 4 5 6 7 8 9 10 11 12 def fibonacci (n ): if n <= 1 : return [1 ] fib = [1 , 1 ] while len (fib) < n: fib.append(fib[len (fib) - 1 ] + fib[len (fib) - 2 ]) return fib r = fibonacci(5 ) print (r)
执行结果:
这不是高效的实现,使用生成器更节省内存。
生成器版本 使用 Python 的生成器,保证代码简洁的同时,还能节省内存:
1 2 3 4 5 6 7 8 9 def fibonacci (n ): a, b = 1 , 1 for _ in range (n): yield a a, b = b, a + b print (list (fibonacci(5 )))
遇到 yield 返回,下次再进入函数体时,从 yield 的下一句开始执行。执行结果:
出镜最多 max 函数是 Python 的内置函数,所以使用它无需 import。
max 有一个 key 参数,指定如何进行值得比较。
1 2 3 4 5 6 7 8 9 10 def mode (lst ): if not lst: return None return max (lst, key=lambda v: lst.count(v)) lst = [1 , 3 , 3 , 2 , 1 , 1 , 2 ] r = mode(lst) print (f'{lst} 中出现次数最多的元素为:{r} ' )
执行结果:
出镜最多的元素有多个时,按照以上方法,默认只返回一个。
下面代码,支持返回多个:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def mode (lst ): if not lst: return None max_freq_elem = max (lst, key=lambda v: lst.count(v)) max_freq = lst.count(max_freq_elem) ret = [] for i in lst: if i not in ret and lst.count(i) == max_freq: ret.append(i) return ret lst = [1 , 3 , 3 , 2 , 1 , 1 , 2 , 3 , 4 ] r = mode(lst) print (f'{lst} 中出现次数最多的元素为:{r} ' )
执行结果:
更长列表 带有一个 * 的参数为可变的位置参数,意味着能传入任意多个位置参数。
key 函数定义怎么比较大小:lambda 的参数 v 是 lists 中的一个元素。
1 2 3 4 5 6 7 8 def max_len (*lists ): return max (*lists, key=lambda v: len (v)) r = max_len([1 , 2 , 3 ], [4 , 5 , 6 , 7 ], [8 ]) print (f'更长的列表是{r} ' )
执行结果:
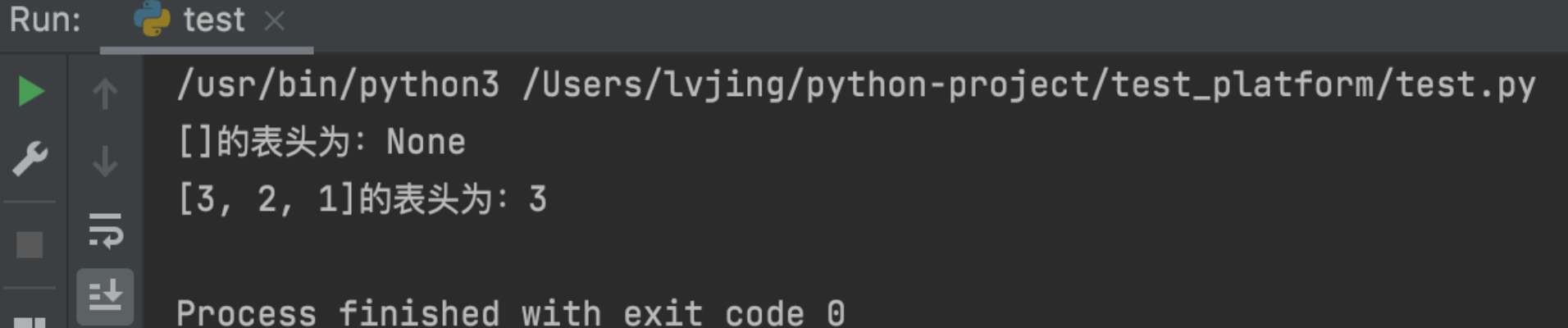
求表头 返回列表的第一个元素,注意列表为空时,返回 None。
通过此例,学会使用 if 和 else 的这种简洁表达。
1 2 3 4 5 6 7 def head (lst ): return lst[0 ] if len (lst) > 0 else None print (f'{[]} 的表头为:{head([])} ' )print (f'{[3 , 2 , 1 ]} 的表头为:{head([3 , 2 , 1 ])} ' )
执行结果为:
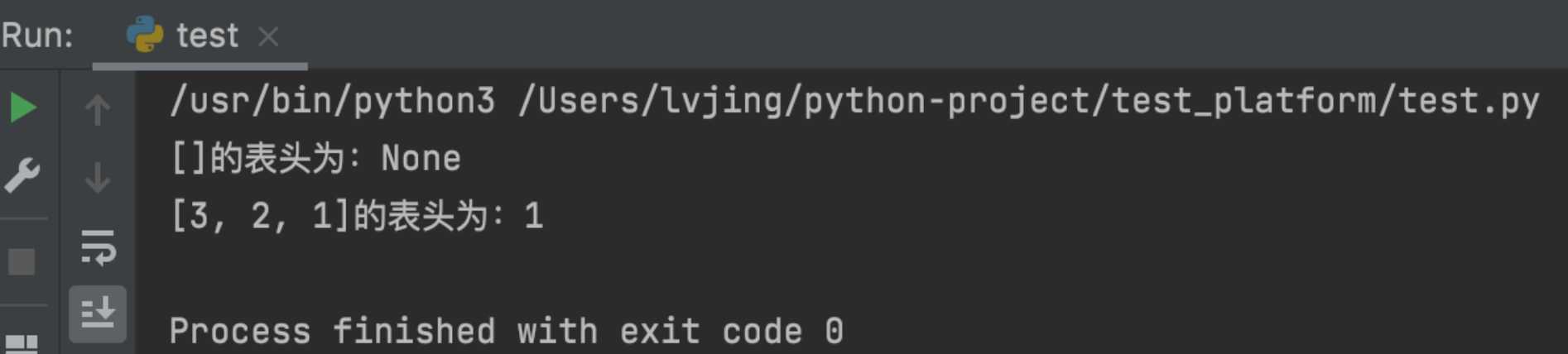
求表尾 求列表的最后一个元素,同样列表为空时,返回 None。
1 2 3 4 5 6 7 def tail (lst ): return lst[-1 ] if len (lst) > 0 else None print (f'{[]} 的表头为:{tail([])} ' )print (f'{[3 , 2 , 1 ]} 的表头为:{tail([3 , 2 , 1 ])} ' )
执行结果:
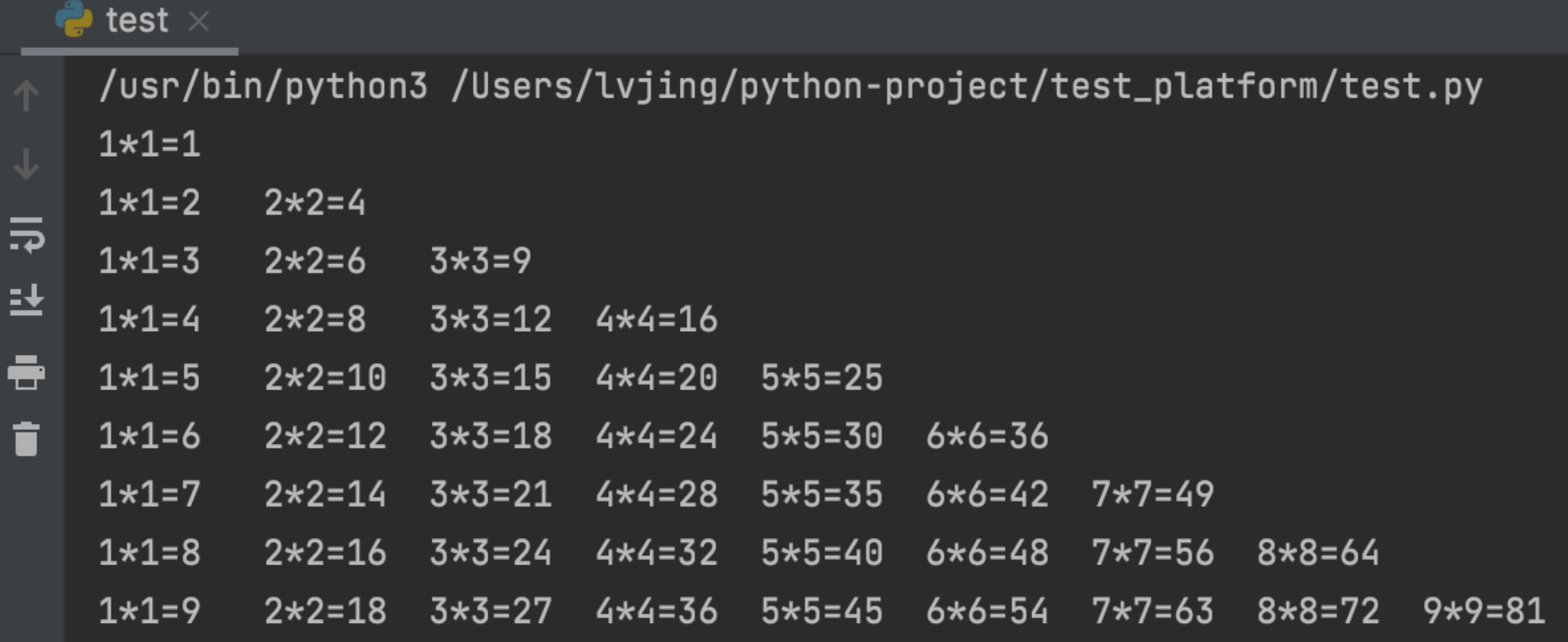
打印乘法表 外层循环一次,print(),换行;内层循环一次,打印一个等式。
1 2 3 4 5 6 7 8 9 10 def mul_table (): for i in range (1 , 10 ): for j in range (1 , i + 1 ): print (str (j) + str ('*' ) + str (j) + "=" + str (i * j), end="\t" ) print () mul_table()
执行结果:
元素对
t[:-1]:原列表切掉最后一个元素;t[1:]:原列表切掉第一个元素;zip(iter1, iter2):实现 iter1 和 iter2 的对应索引处的元素拼接。
1 2 3 4 5 6 7 def pair (t ): return list (zip (t[:-1 ], t[1 :])) print (pair([1 , 2 , 3 , 4 ]))
执行结果:
样本抽样 内置 random 模块中,有一个 sample 函数,实现“抽样”功能。
下面例子从 100 个样本中,随机抽样 10 个。
首先,使用列表生成式,创建长度为 100 的列表 lst;
然后,sample 抽样 10 个样本。
1 2 3 4 5 6 from random import randint, samplelst = [randint(0 , 20 ) for _ in range (50 )] print (lst)lst_sample = sample(lst, 10 ) print (lst_sample)
执行结果:
重洗数据集 内置 random 中的 shuffle 函数,能重洗数据。
值得注意,shuffle 是对输入列表就地(in place)洗牌,节省存储空间。
1 2 3 4 5 6 7 from random import randint, shufflelst = [randint(0 , 20 ) for _ in range (50 )] print (f'重洗前数据{lst} ' )shuffle(lst) print (f'重洗后数据{lst} ' )
执行结果: